
Einleitung
Heute werden der Bedeckungsgrad des Himmels und die Typen der am Himmel vorhandenen Wolken noch immer weitgehend von menschlichen Beobachterinnen und Beobachtern bestimmt. Und das im 21. Jahrhundert! Die Nachteile sind offensichtlich: die auf menschlicher Beobachtung basierenden Daten sind immer zu einem gewissen Grade subjektiv und nur bedingt vergleichbar. Dazu ist die zeitliche Auflösung der Messungen gering, für die Nächte und wohl auch die meisten Feiertage und Wochenenden fehlen die Daten komplett. Deshalb braucht es eine neue, computerbasierte Lösung. Während meinem Zivildiensteinsatz am Physikalisch-Meteorologischen Observatorium in Davos / World Radiation Center (PMOD/WRC) habe ich an einem Algorithmus gearbeitet, der Wolken auf Infrarotbildern des gesamten Himmels erkennen kann. Dabei habe ich Techniken des überwachten maschinellen Lernens verwendet. In der Folge werde ich die Grundideen des Algorithmus kurz vorstellen und Beispiele von ausgewerteten Himmelsbildern zeigen.
Der Grundalgorithmus

Die vom PMOD/WRC entwickelte infrared cloud camera IRCCAM (oben links im Bild) nimmt rund um die Uhr jede Minute ein Infrarotbild des gesamten Himmels auf (sprich misst in jedem Pixel die gesamte im Spektrum von 8 bis 14 µm eintreffende Strahldichte in Watt pro Quadratmeter pro Steradiant). Sind die Bodentemperatur, die Luftfeuchtigkeit und der Luftdruck bekannt, so kann zudem ein theoretisches clear-sky model berechnet werden. Dieses gibt die Strahldichte wieder, die der unbedeckte Himmel abgeben würde. Durch Vergleichen der gemessenen Daten mit dem theoretischen Modell können die Wolken detektiert werden: weicht die gemessene Strahldichte von der theoretischen Strahldichte zu stark ab, so muss sich in diesem Punkt eine Wolke befinden. Diese sind nämlich wärmer als der unbedeckte Himmel, da sie tiefer liegen und von der Erde abgestrahlte Wärme aufnehmen, weshalb sie im Messbereich der IRCCAM mehr (Schwarzkörper-)Strahlung aussenden. Einen sehr simplen aber dennoch ziemlich effektiven Wolkenerkennungs-Algorithmus kann man basierend auf diesen Ideen in zwei Matlab-Zeilen umsetzen:
diff = himmel_exp - himmel_th; wolken = diff(diff > schwellenwert);
Die erste Zeile berechnet die Strahlungsdichte-Differenz zwischen den gemessenen und den theoretischen Daten, die zweite Zeile weist diejenigen Einträge der Differenz-Matrix zur Wolken-Matrix zu, die grösser als ein fix gewählter Schwellenwert sind. Ein typisches ausgewertetes Himmelsbild dieses Algorithmus sieht so aus:

Links sieht man eine Aufnahme des Himmels im sichtbaren Spektrum, rechts im Infrarot. In der Mitte werden alle detektierten Wolken angezeigt. Die dicken Wolken werden ohne Probleme erkannt, bei den dünneren Wolken allerdings scheitert der Algorithmus. Der Grund dafür ist schnell erklärt: die absoluten Strahldichte-Werte der dünnen Wolken weichen nur minim von den Werten des unbedeckten Himmels ab (das Infrarot-Bild oben rechts zeigt dies klar auf), deshalb können sie nicht über die absolute Strahldichte-Differenz detektiert werden. Es musste also ein raffinierterer Algorithmus her. Genau damit habe ich mich während meinem Zivildienst beschäftigt.
Neue Ideen
Zu Beginn meines Einsatzes habe ich mich mit allen Einzelheiten des bestehenden Algorithmus auseinandergesetzt, sprich mit dem Prinzip des clear-sky models und der Kalibrierung der Messdaten (das im Bild oben gezeigte Infrarot-Bild ist entzerrt worden, damit die Winkelabhängigkeiten korrekt wiedergegeben werden). Dann fügte ich Skripts wie etwa das Clustering hinzu – das Anzeigen der Schwerpunkte aller Wolken-Cluster mit einem roten Quadrat (im Bild oben in der Mitte zu sehen). Das Clustering erlaubt es dem Programm, einzelne Wolken zu unterscheiden.
Schliesslich machte ich mich an die Hauptaufgabe: das Detektieren der dünnen Wolken. Ich kam schnell auf die Idee, die Detektion basierend auf den relativen Strahldichte-Werten zu versuchen – sprich wie stark die Messwerte von einem Pixel zum nächsten schwanken. Der Gedanke dahinter ist, dass die von Wolken ausgesendete Strahlungsleistung lokal stark variiert, während von einem klaren Himmel eine kontinuierliche Strahlungsleistungs-Verteilung zu erwarten ist. Ich versuchte verschiedene Ansätze, welche die Varianz von Messwerten in Pixel-Quadraten und die Optimierung über einen genetischen Algorithmus umfassten, diese detektierten aber die dünnen Wolken auch nicht wie gewünscht und deshalb möchte ich nicht weiter auf sie eingehen.
Der Algorithmus
Auf einen vielversprechenden Ansatz zur Lösung des Problems stiess ich schliesslich in einem Paper von Luo et al. (2018). In diesem wird ein linearer Classifier (mehr dazu in meinem Beitrag Neuronale Netze) beschrieben, welcher basierend auf der lokalen Struktur eines Bildes “Wolken-Quadrate” erkennt. Ich habe diesen Algorithmus in MATLAB und basierend auf den IRCCAM Messdaten umgesetzt. Dazu bereitete ich ein Trainings-Set bestehend aus 100 Bildern vor. Auf Aufnahmen im sichtbaren Spektrum zeichnete ich Quadrate ein, die entweder zu einer Wolke oder zum freien Himmel gehören. Ich wählte nur Bilder, welche dünne Wolken enthalten, damit der Algorithmus speziell auf diese trainiert wird. In diesem Zusammenhang ist der Titel dieses Beitrages zu verstehen: ich habe mich während dem Zivildienst immer über Tage mit dünnen Wolken gefreut, da ich durch sie potentiell noch bessere Trainingsdaten erhalten würde. Schliesslich programmierte ich ein Skript, welches dem sichtbaren Bild das zeitlich passende Infrarot-Bild zuweist und beide kalibriert, so dass sie übereinander gelegt werden können. Das Skript wählt dann das im sichtbaren Bild markierte Quadrat im Infrarot-Bild aus und berechnet aus der Struktur des Pixel-Quadrates vier Werte, wie in Luo et al. beschrieben.
Basierend auf den vier mal hundert Werten trainierte ich den linearen Classifier. Indem man Infrarotaufnahmen des gesamten Himmels in Quadrate aufteilt und mit dem Classifier bestimmt, ob das Quadrat Wolken oder klaren Himmel enthält, kann der gesamte Himmel klassifiziert werden. Resultierende ausgewertete Himmelsbilder sind hier zu sehen:
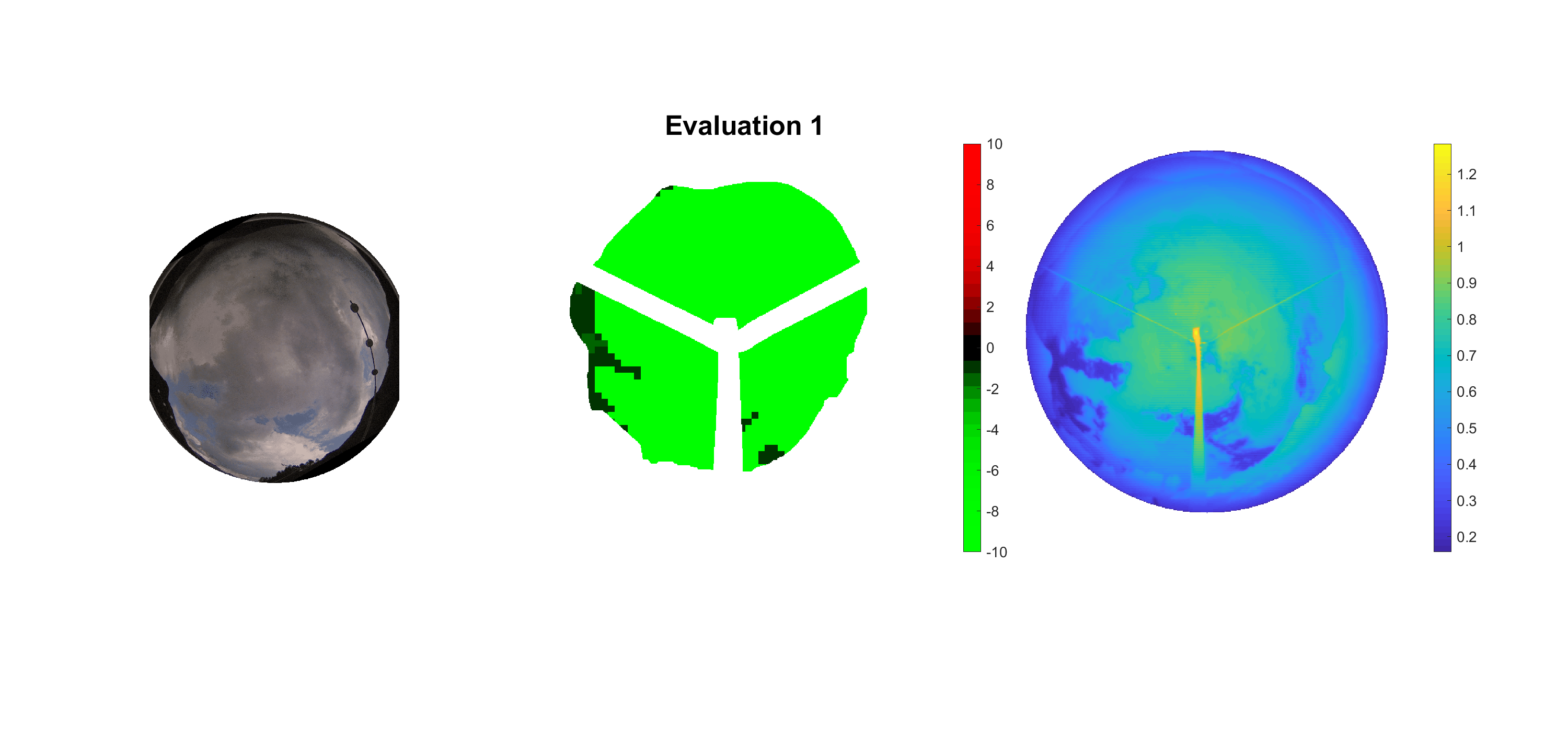

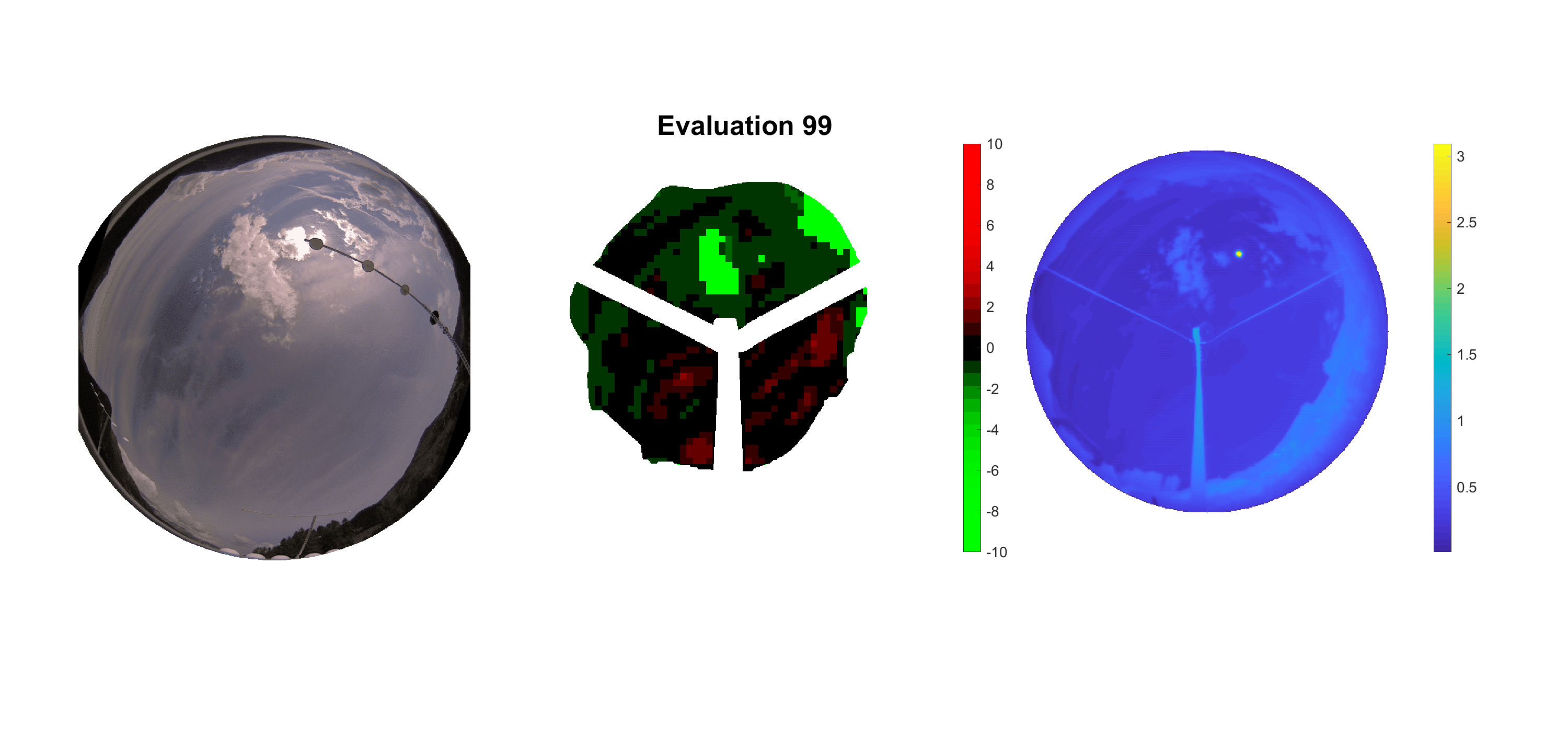

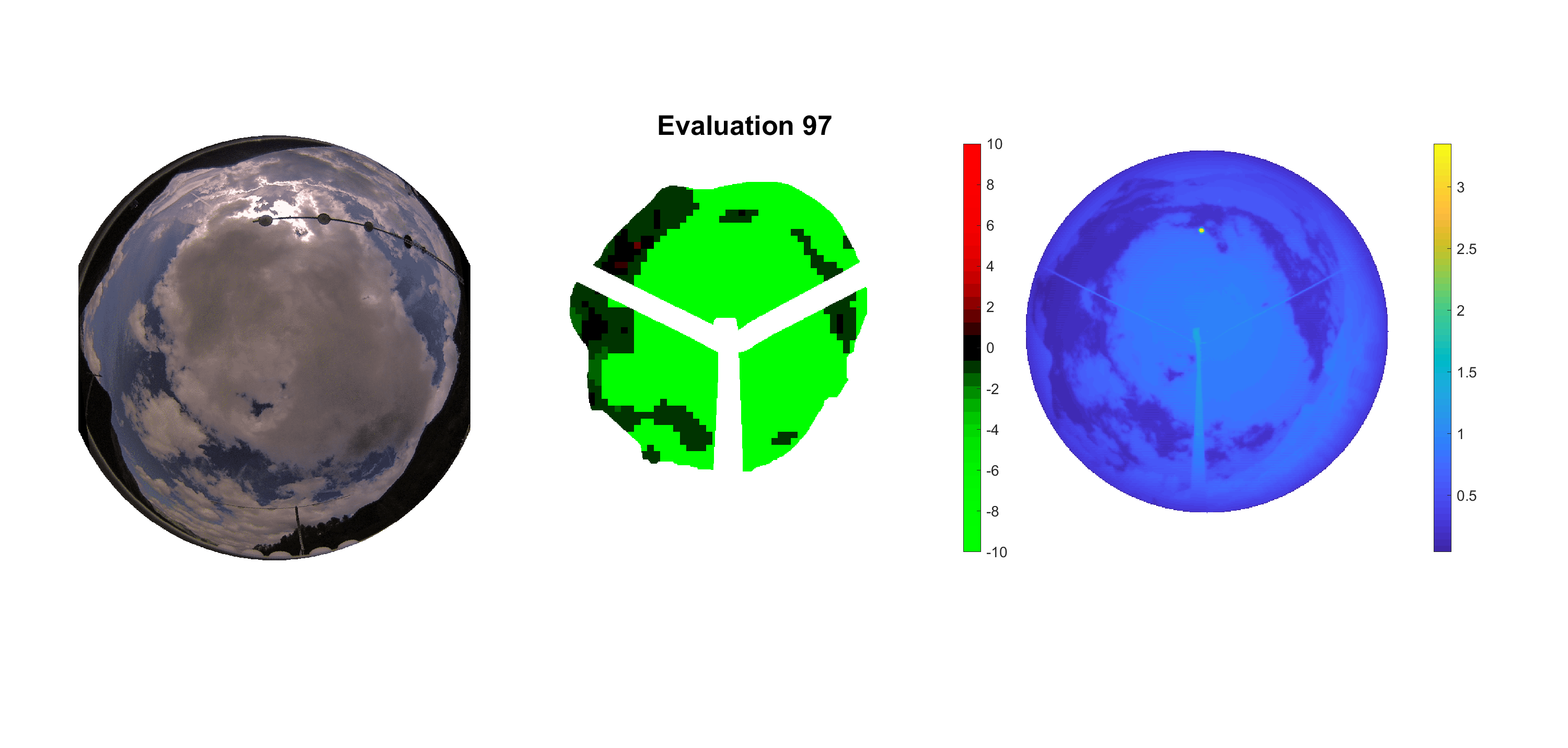
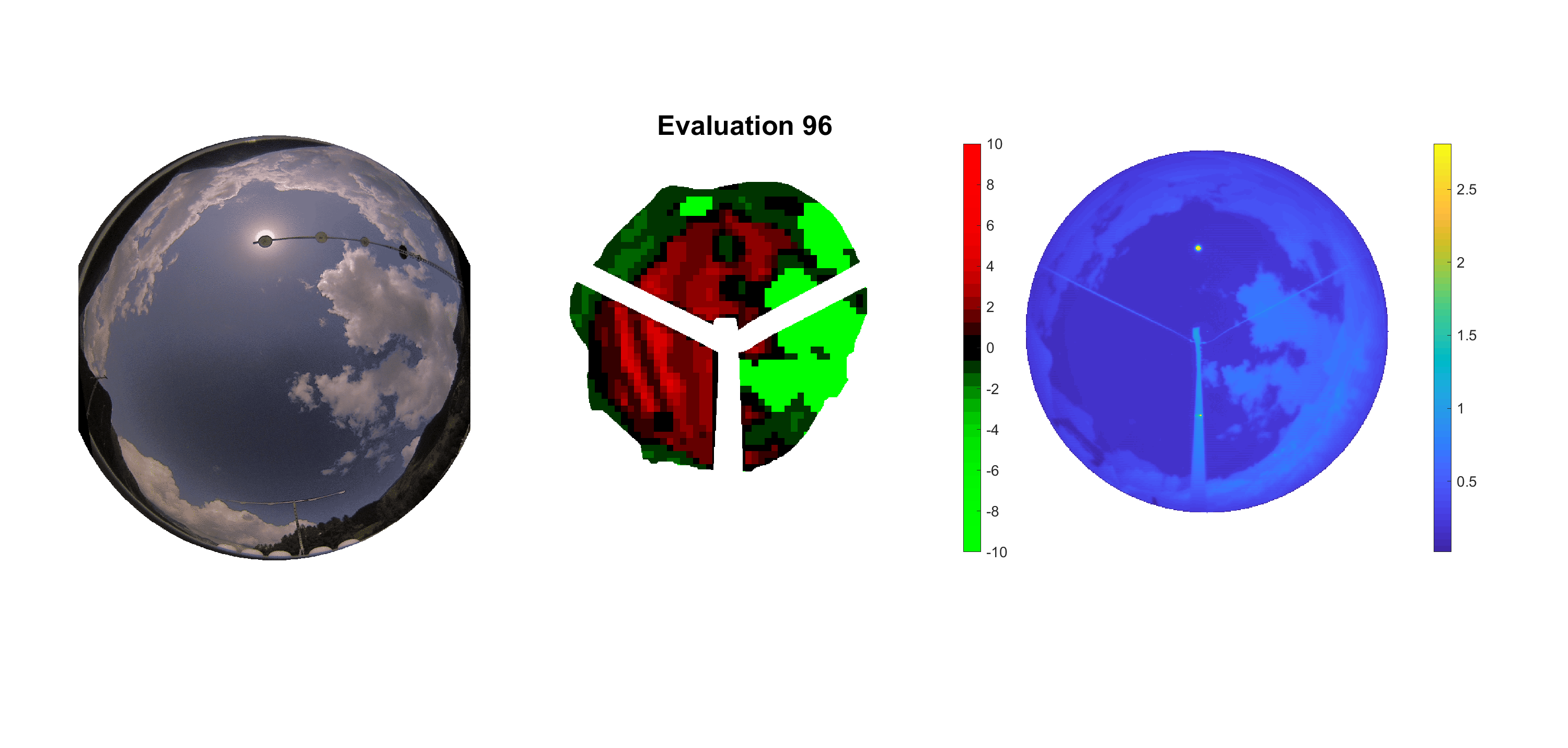
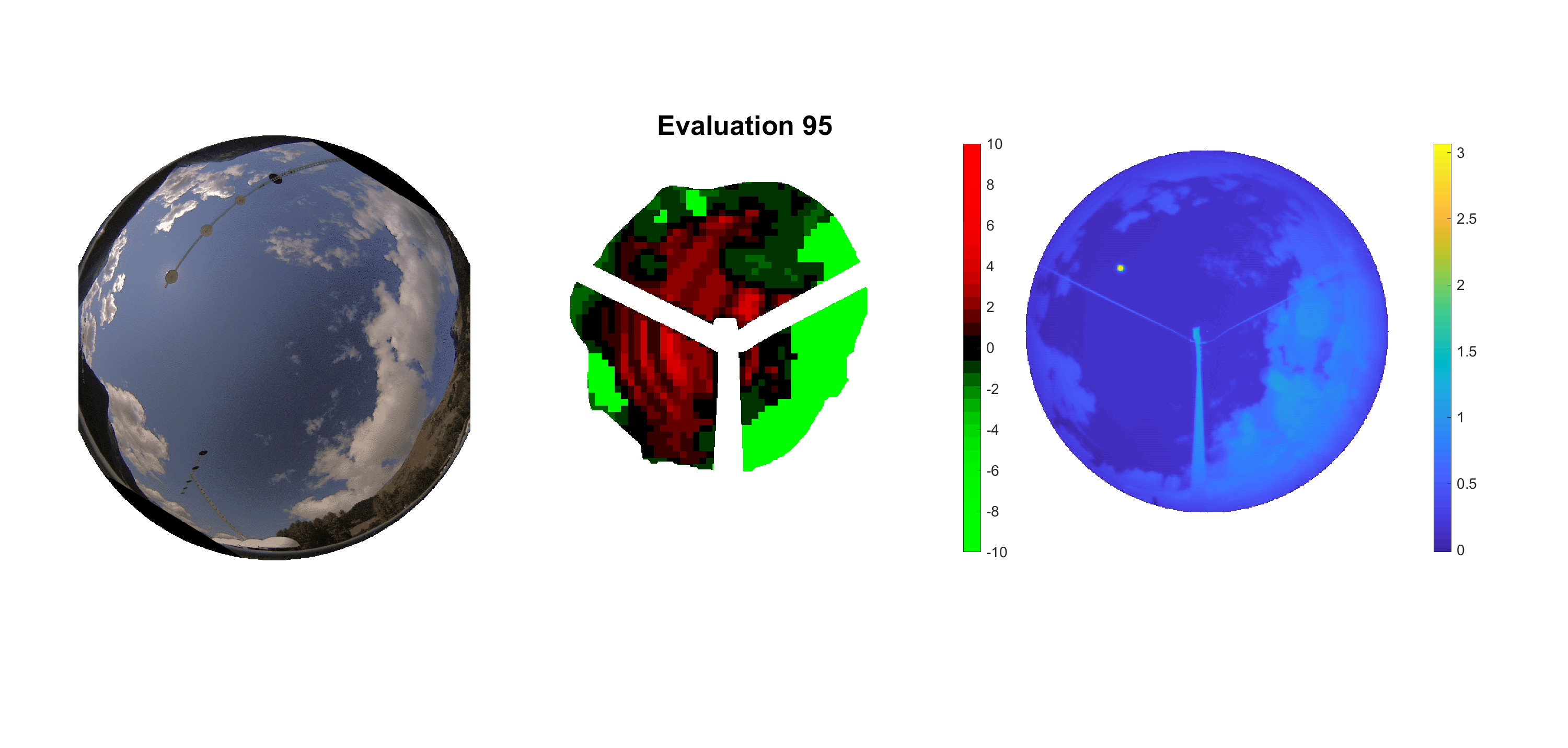
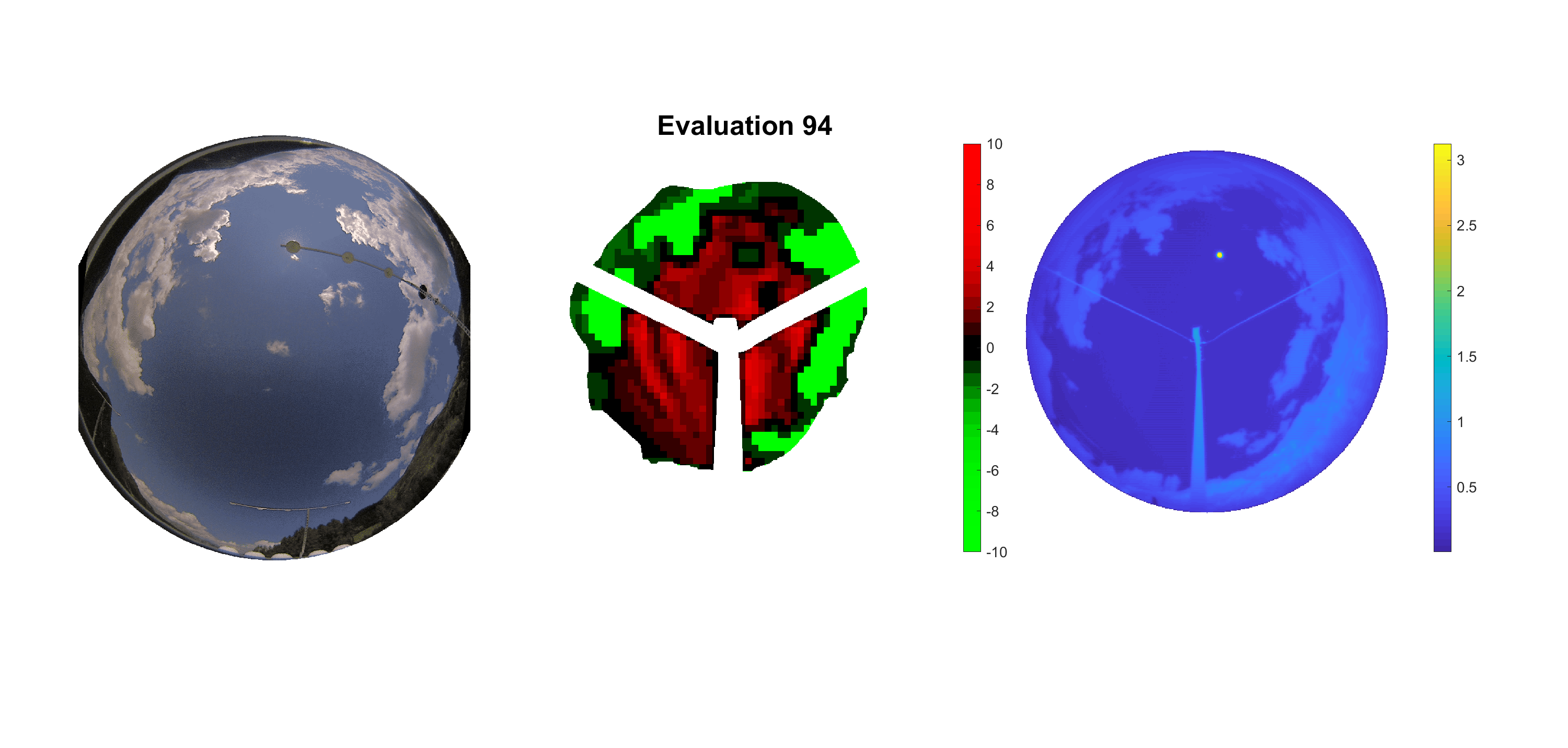


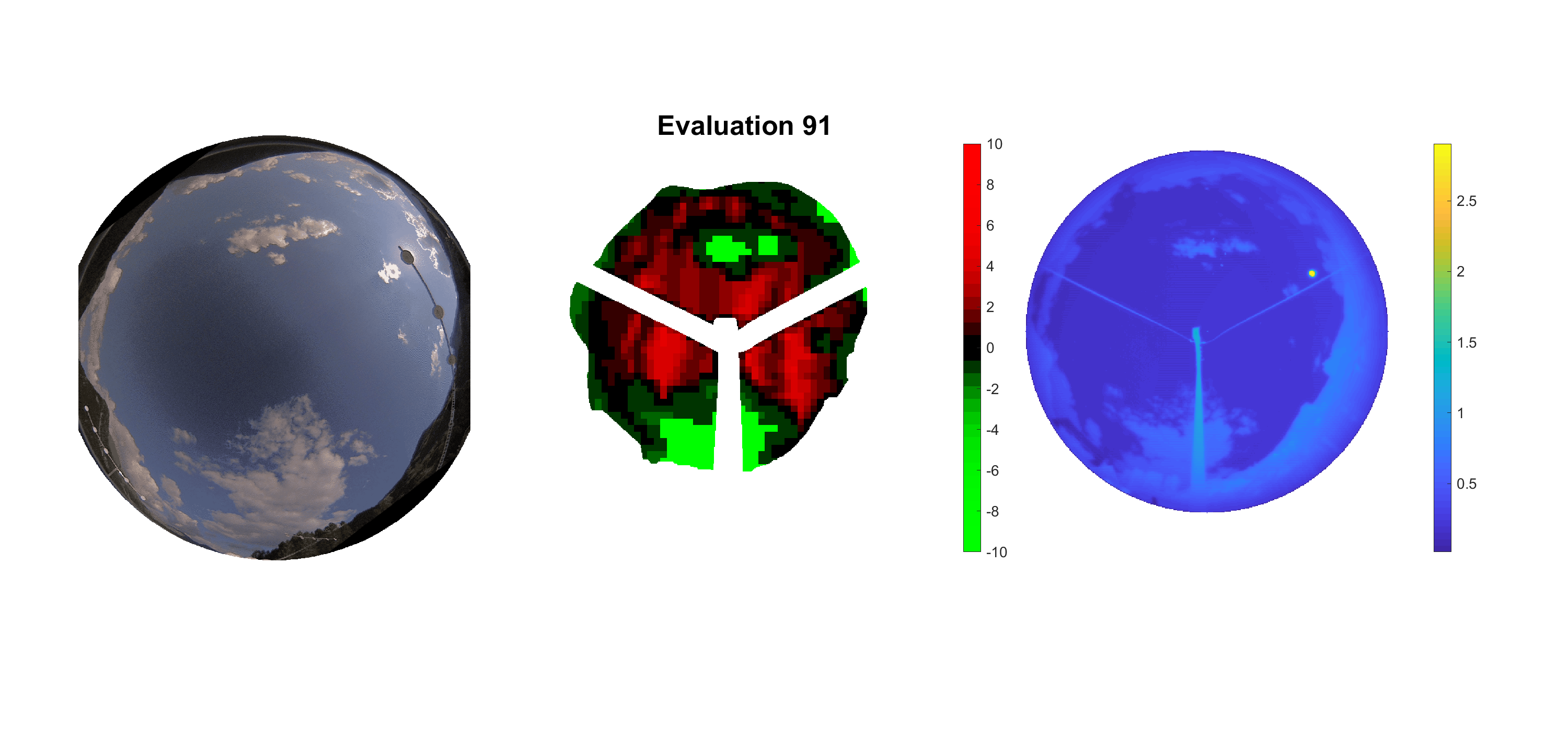
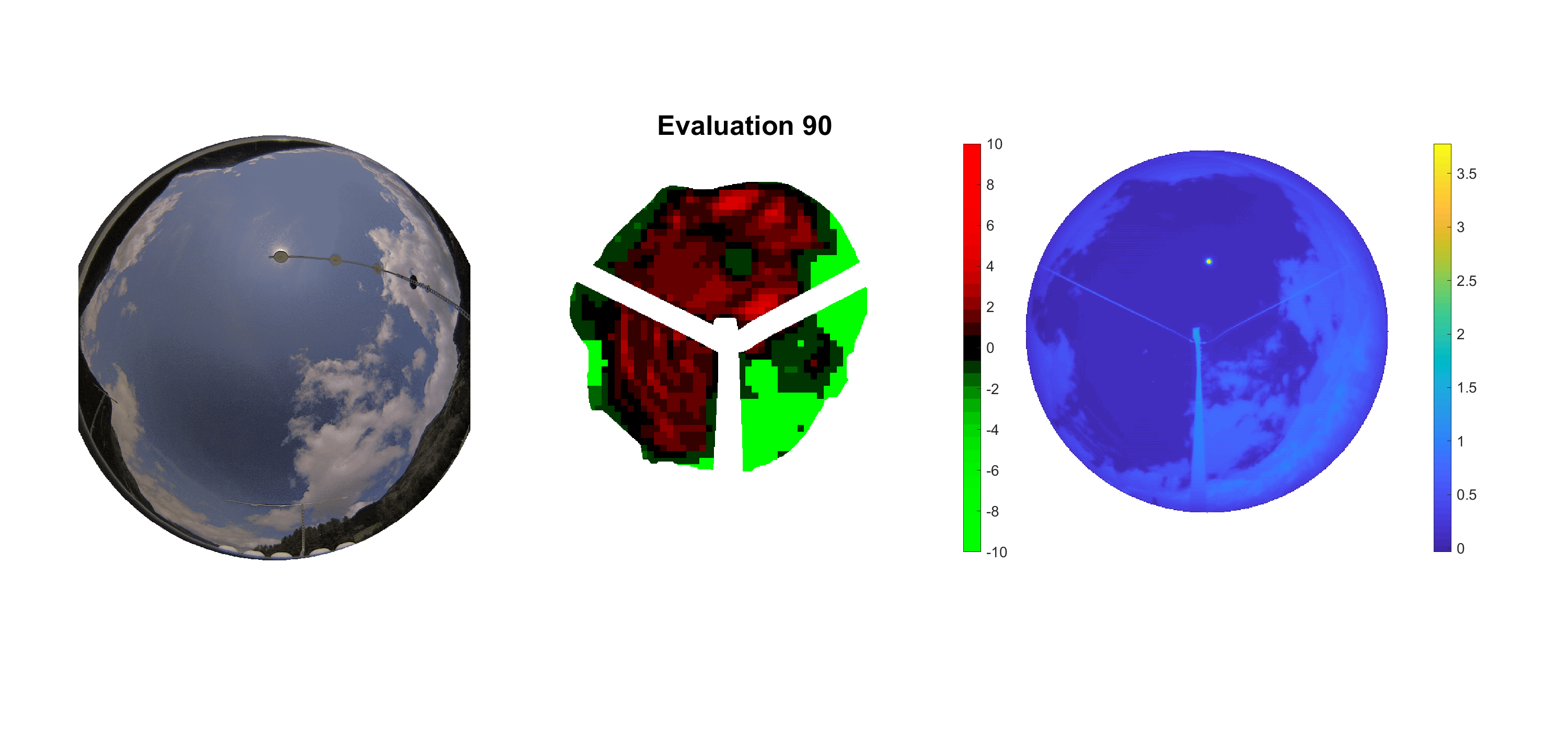
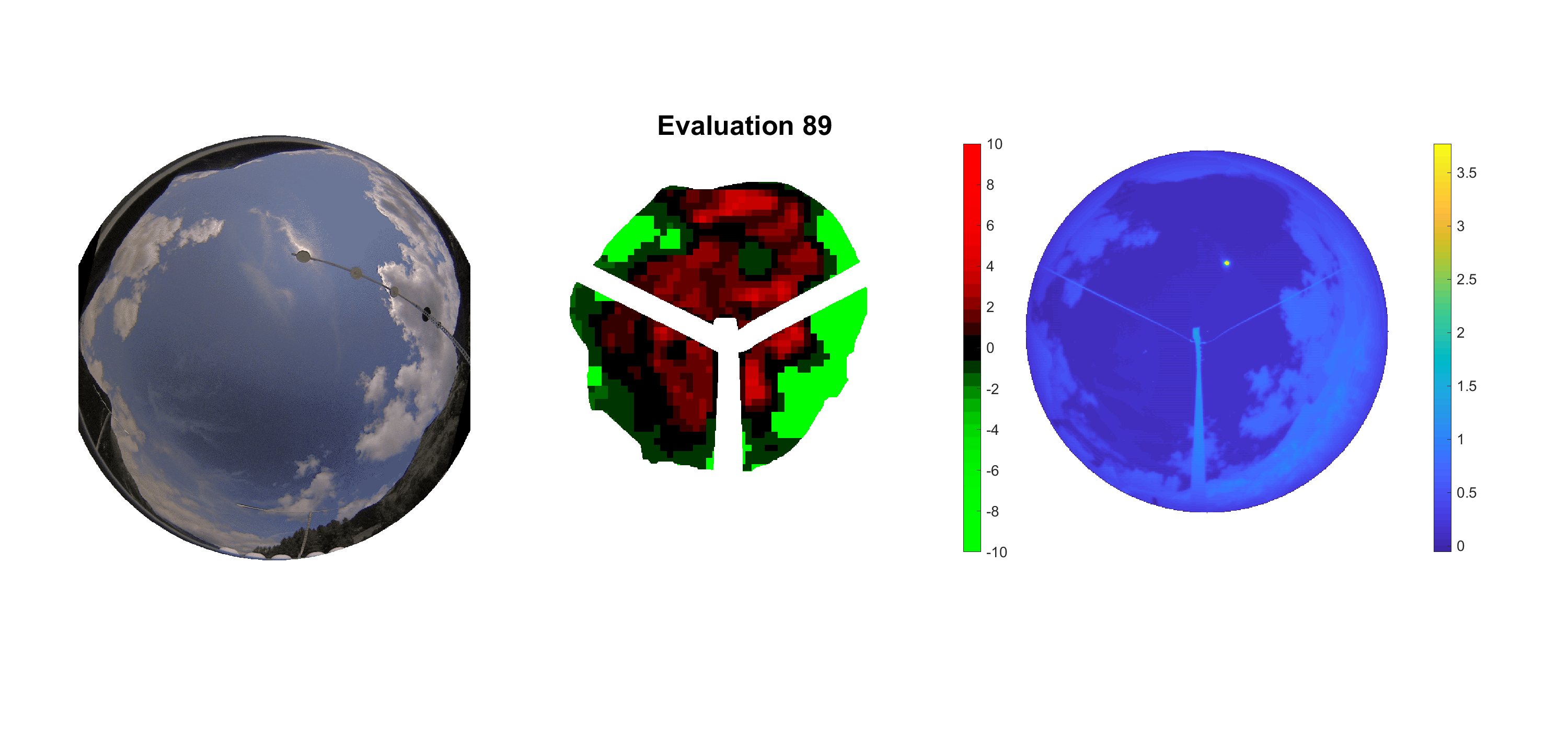

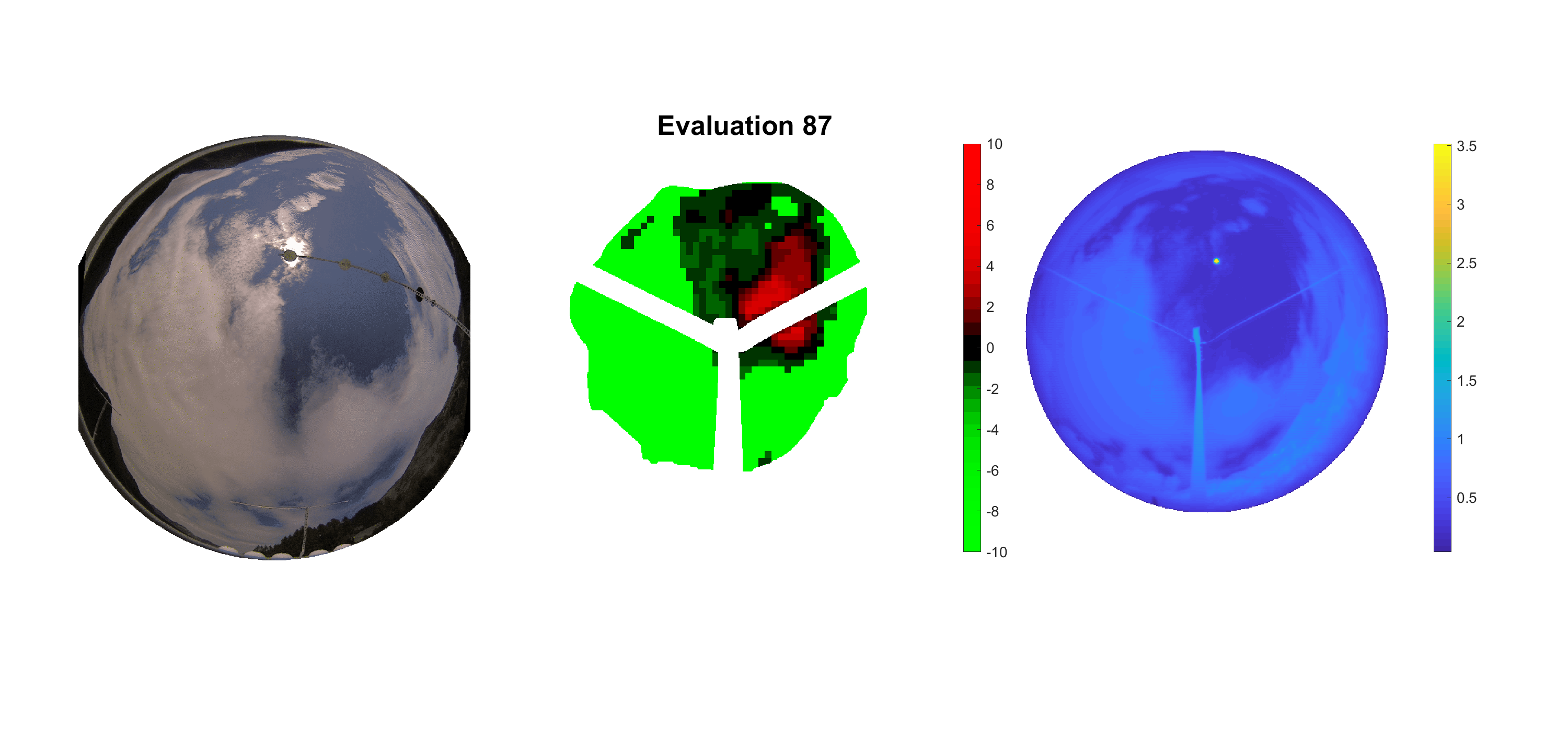
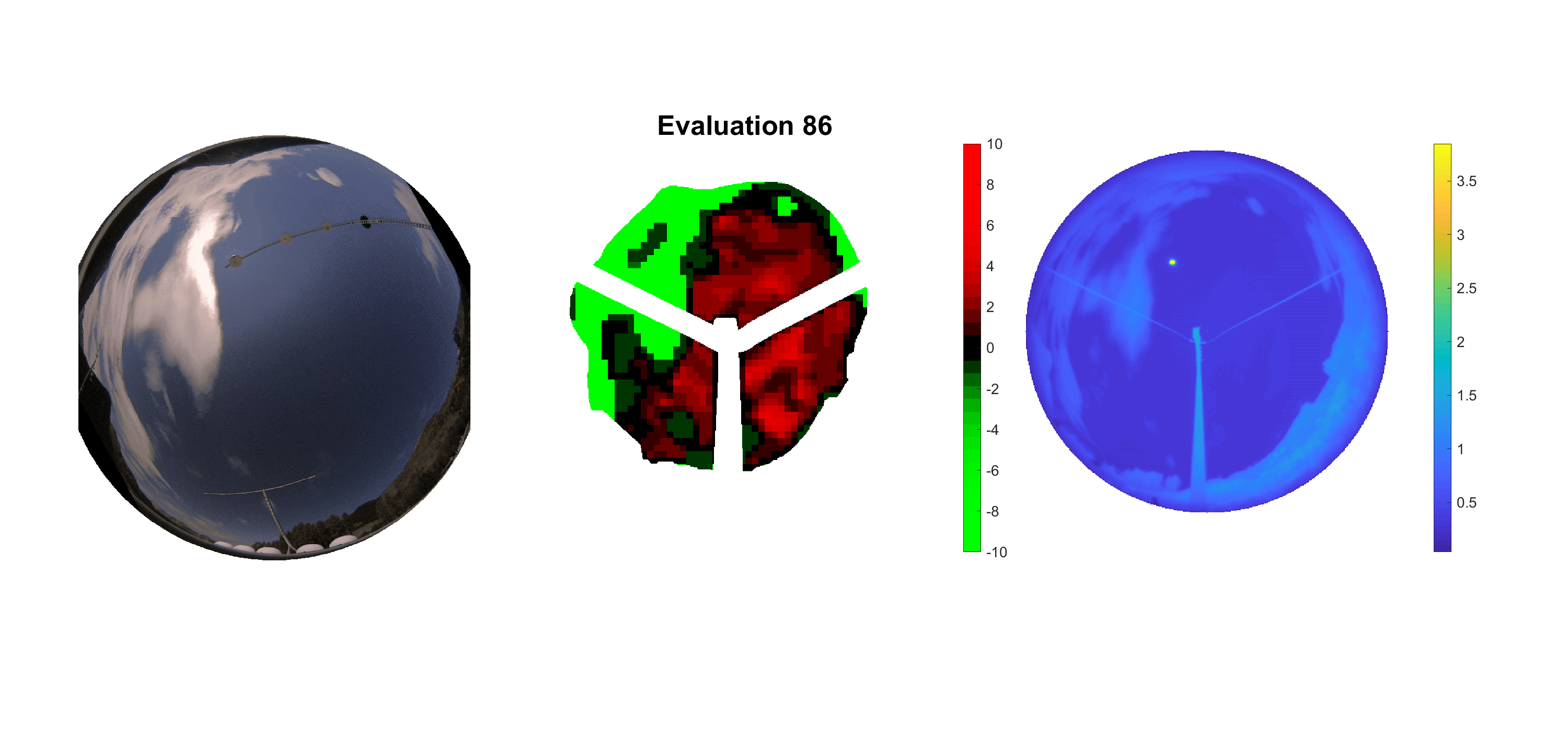



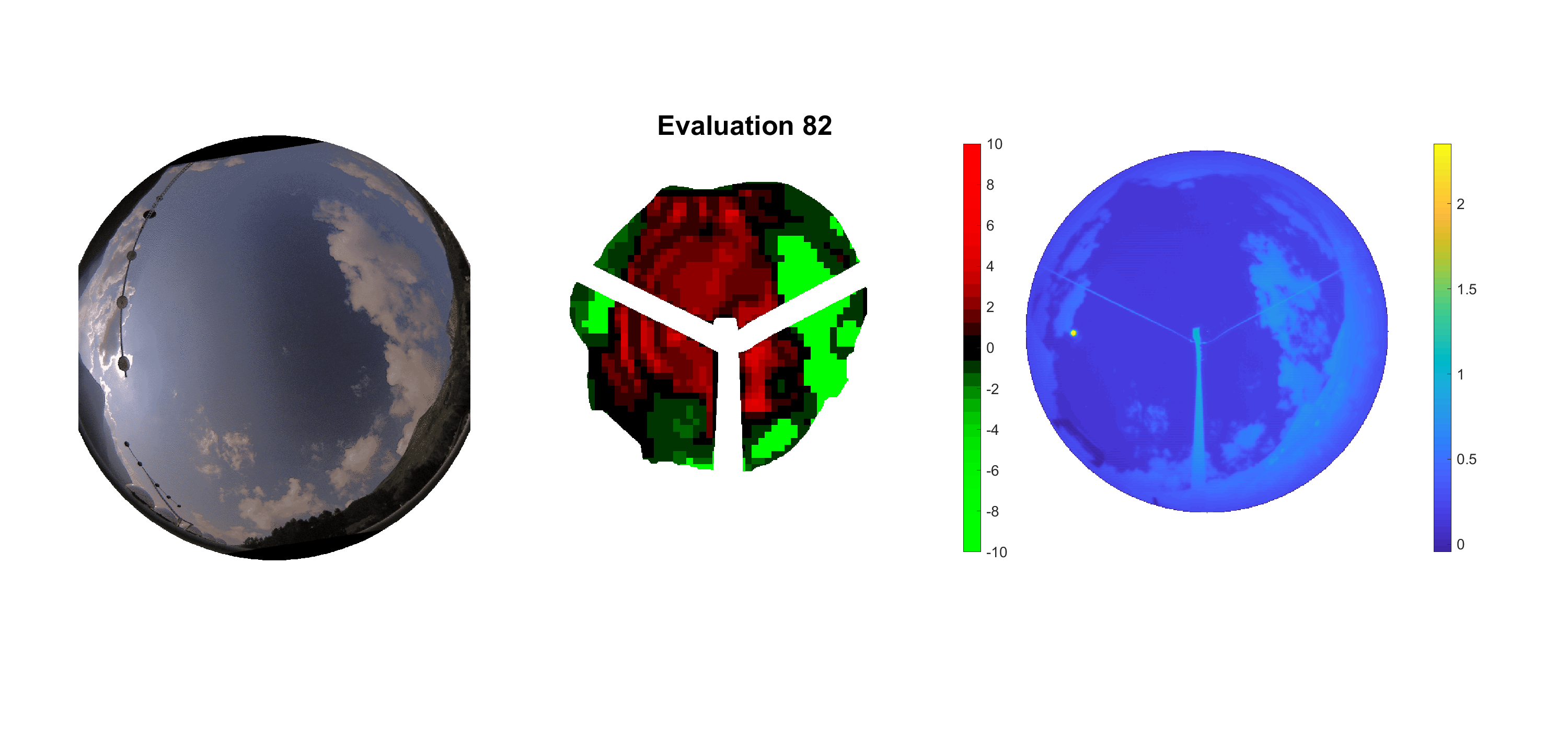
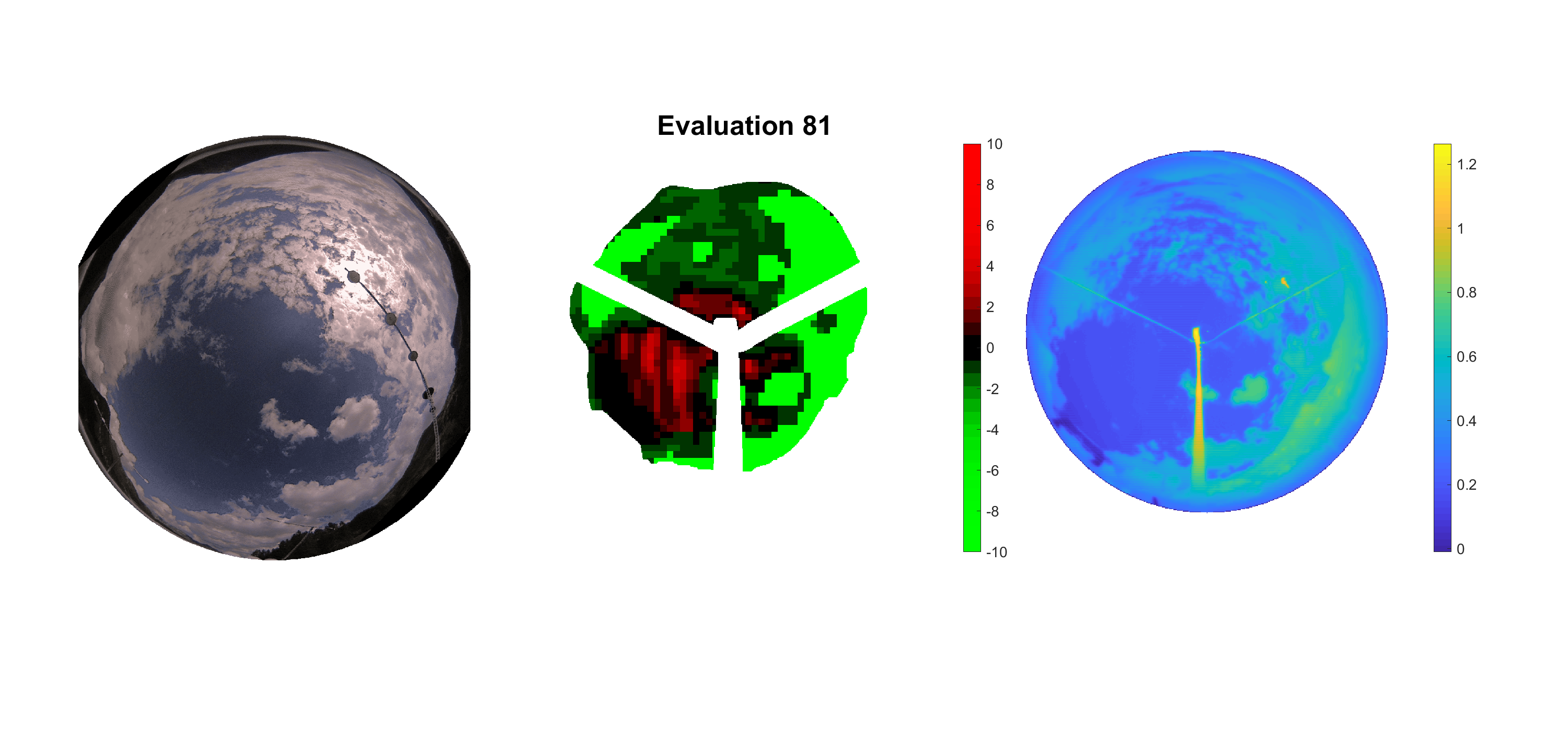

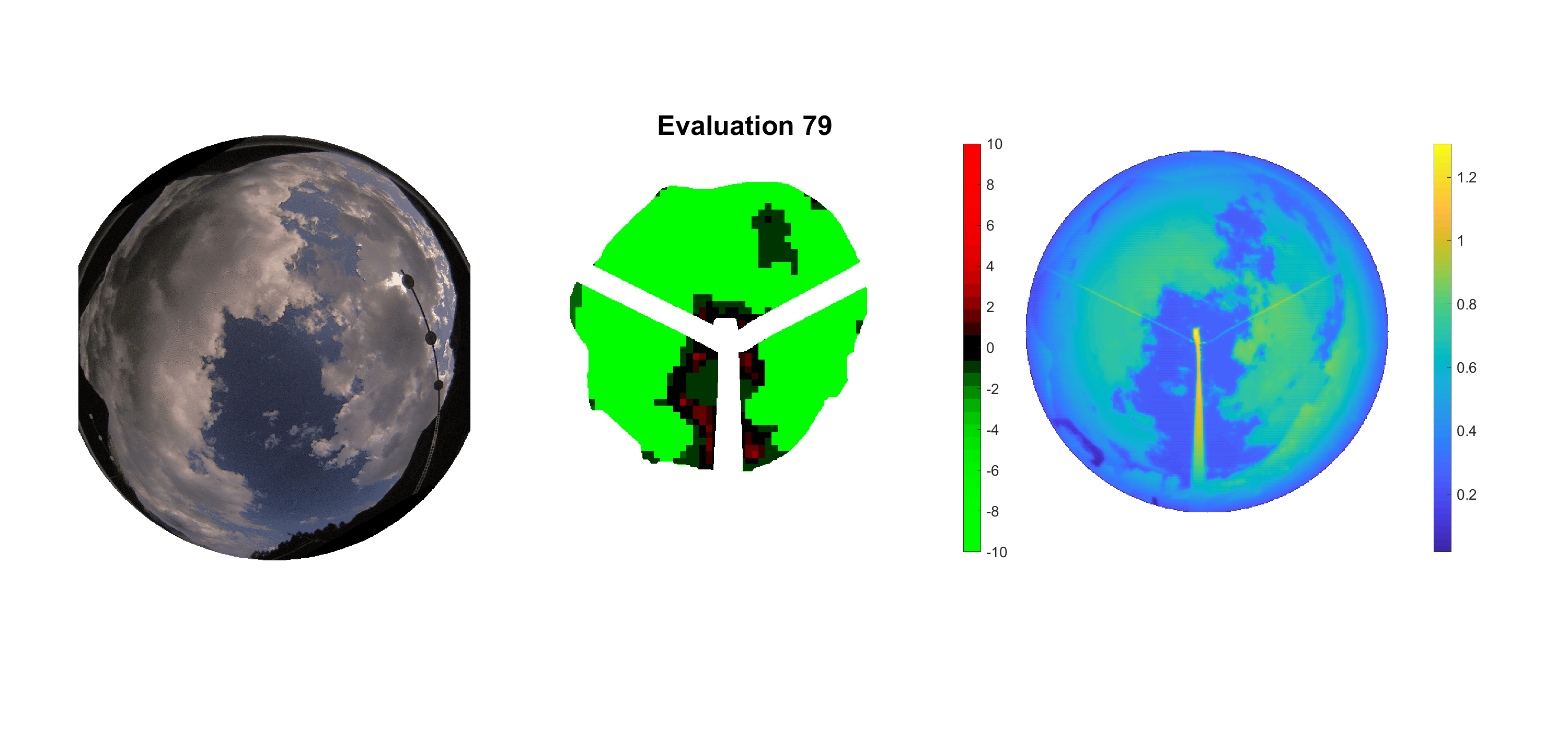
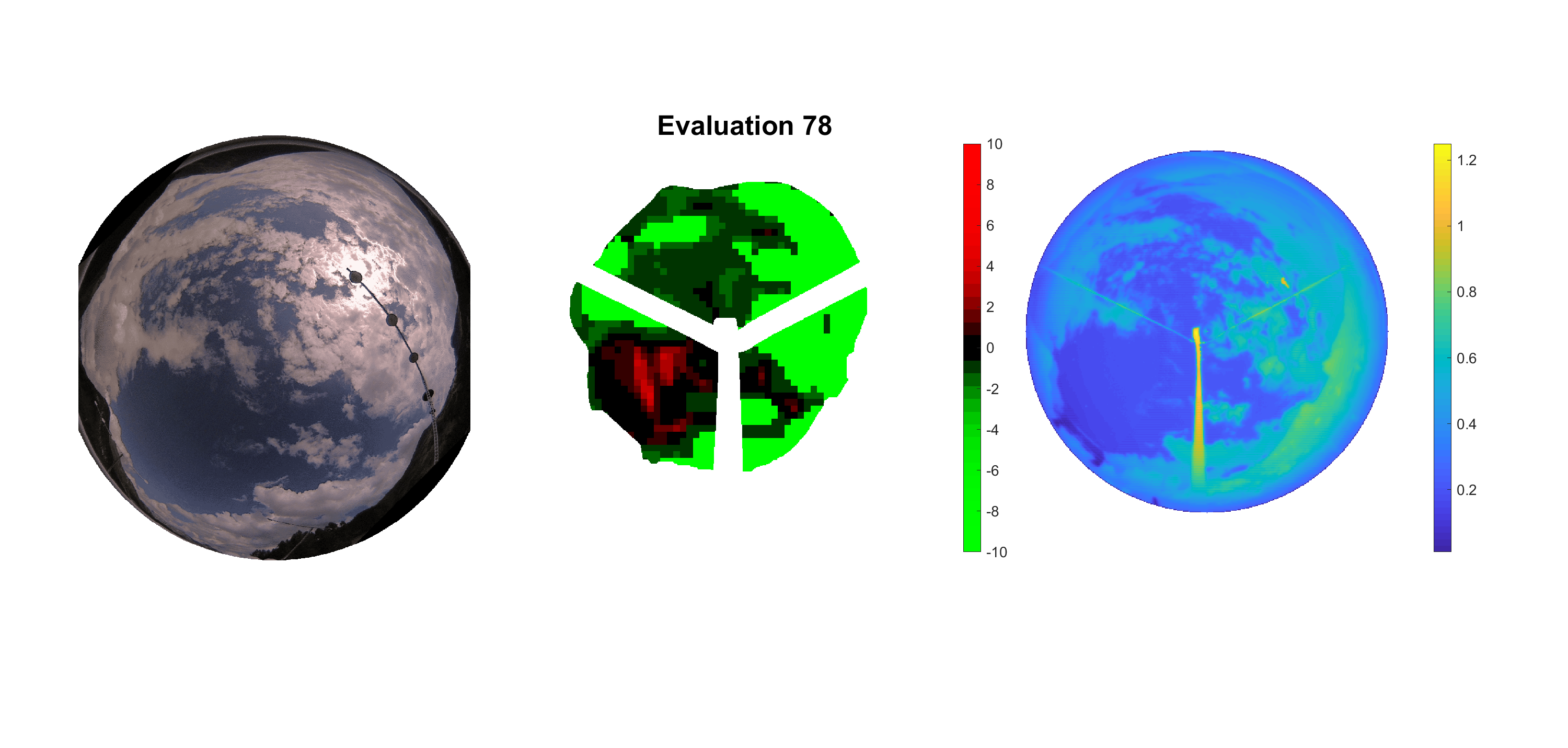


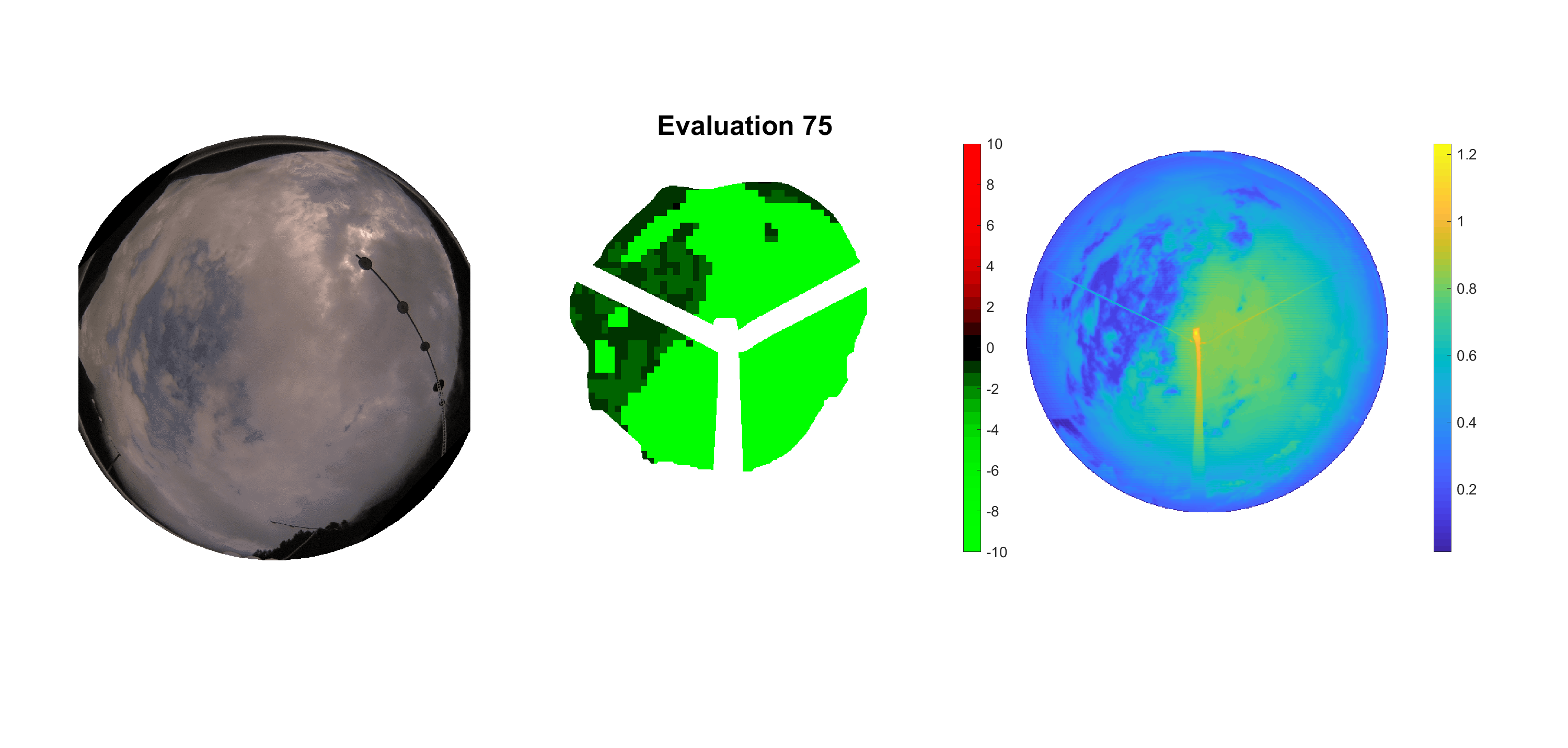
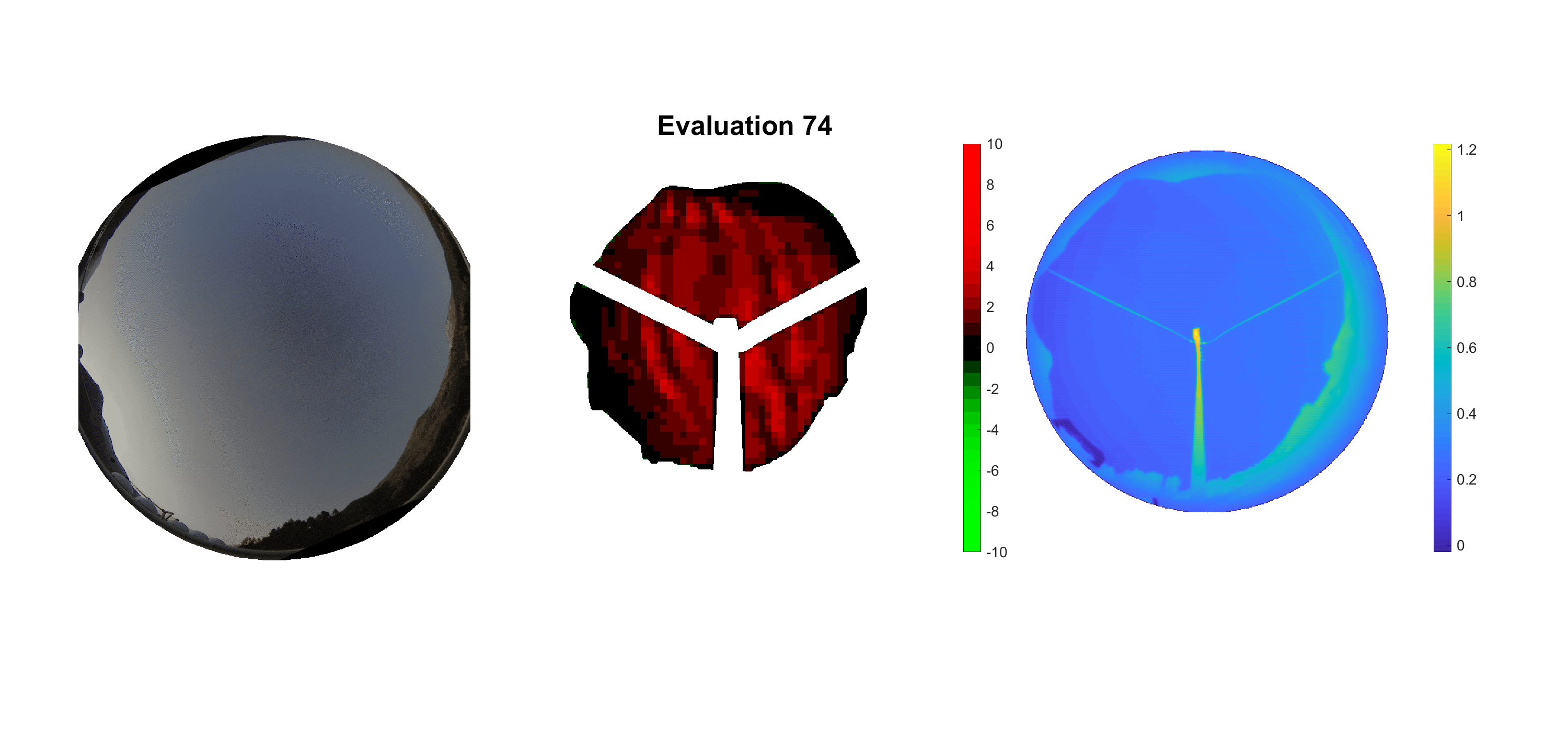
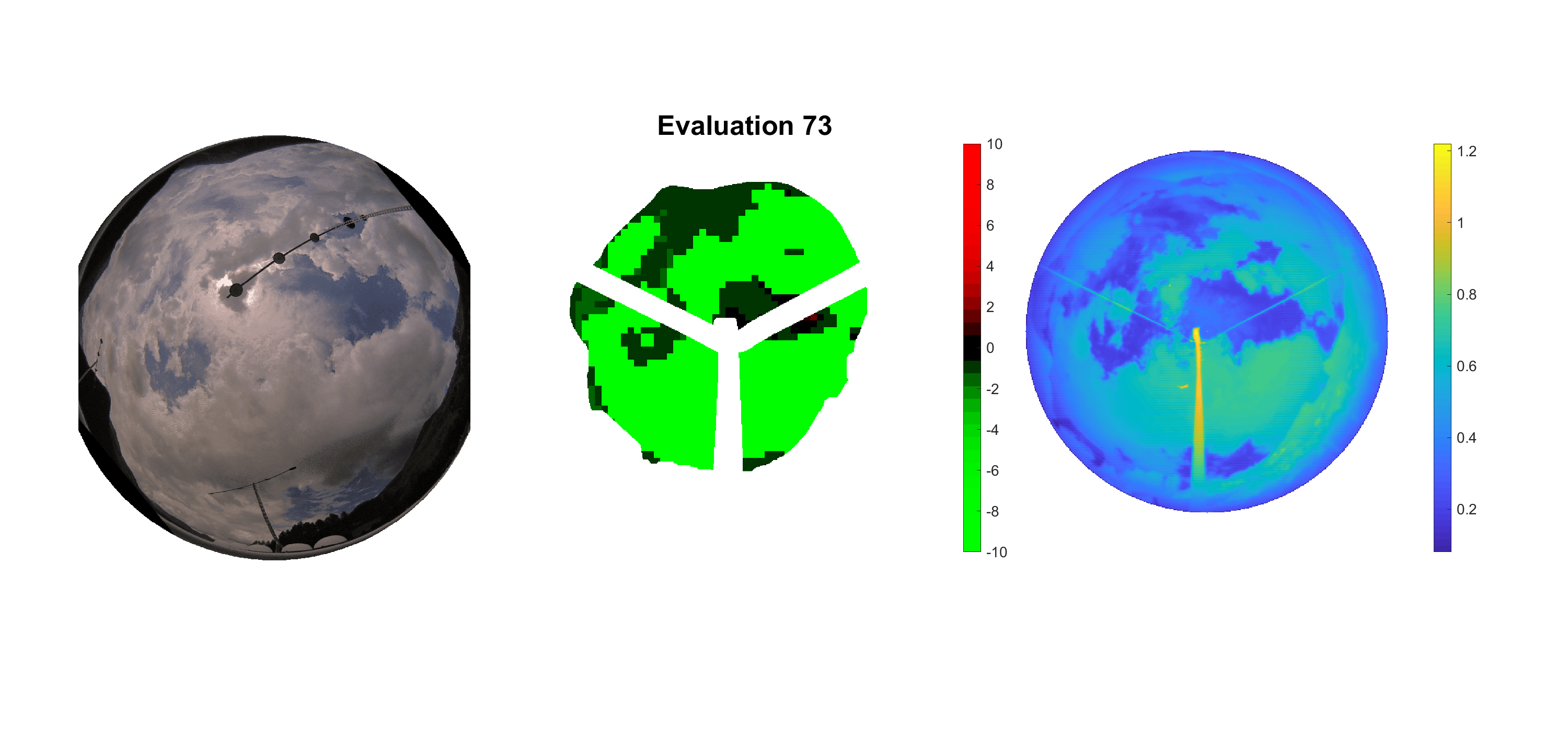
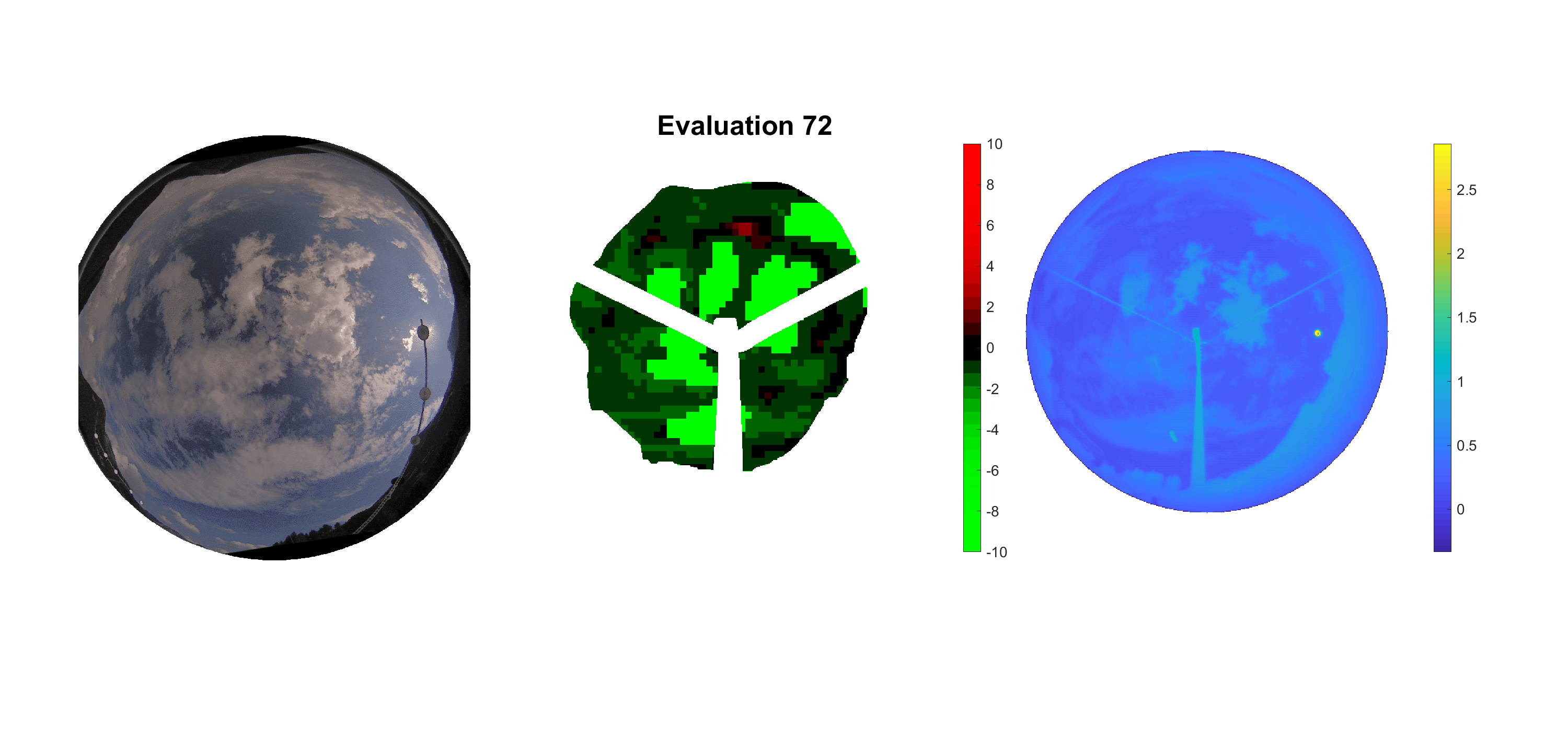
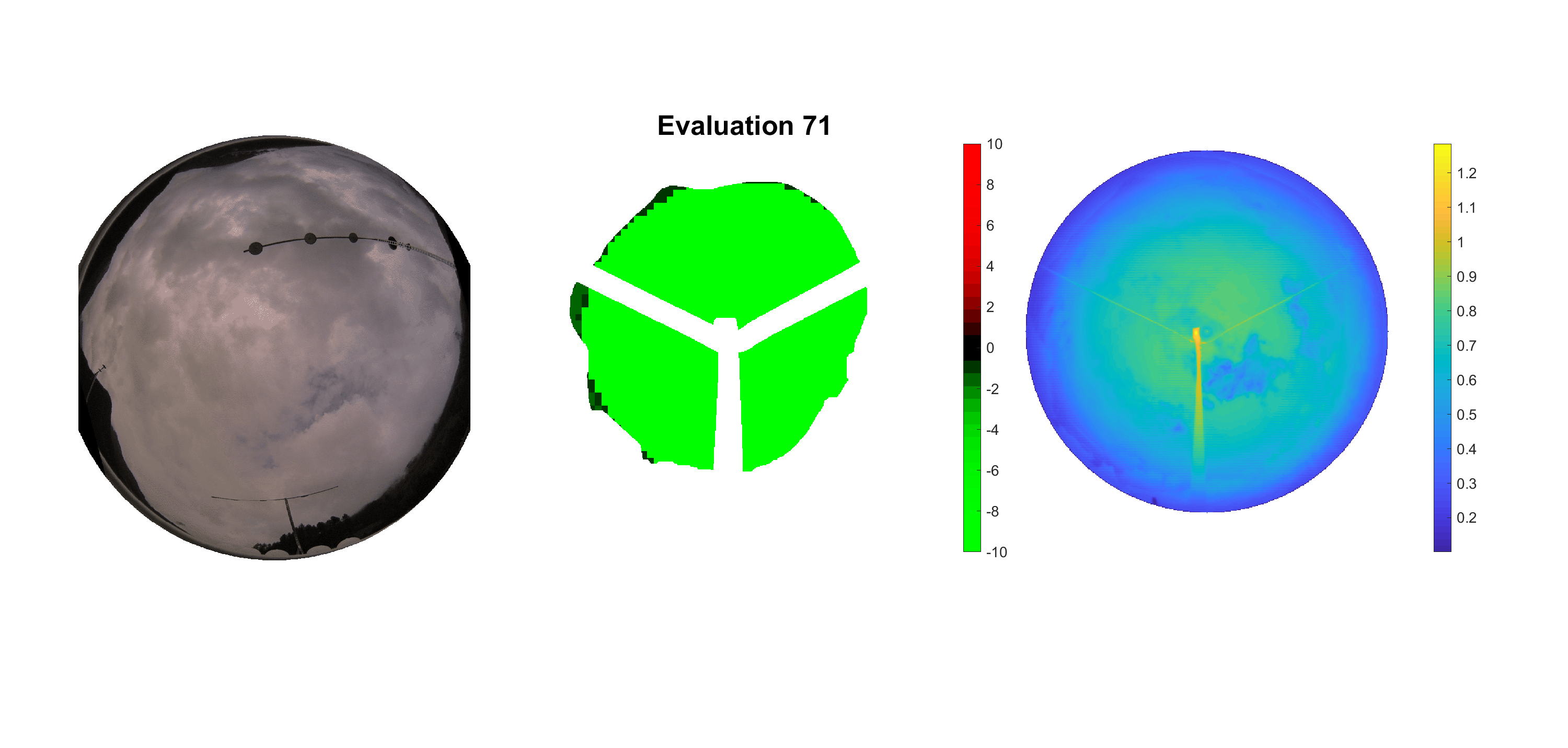
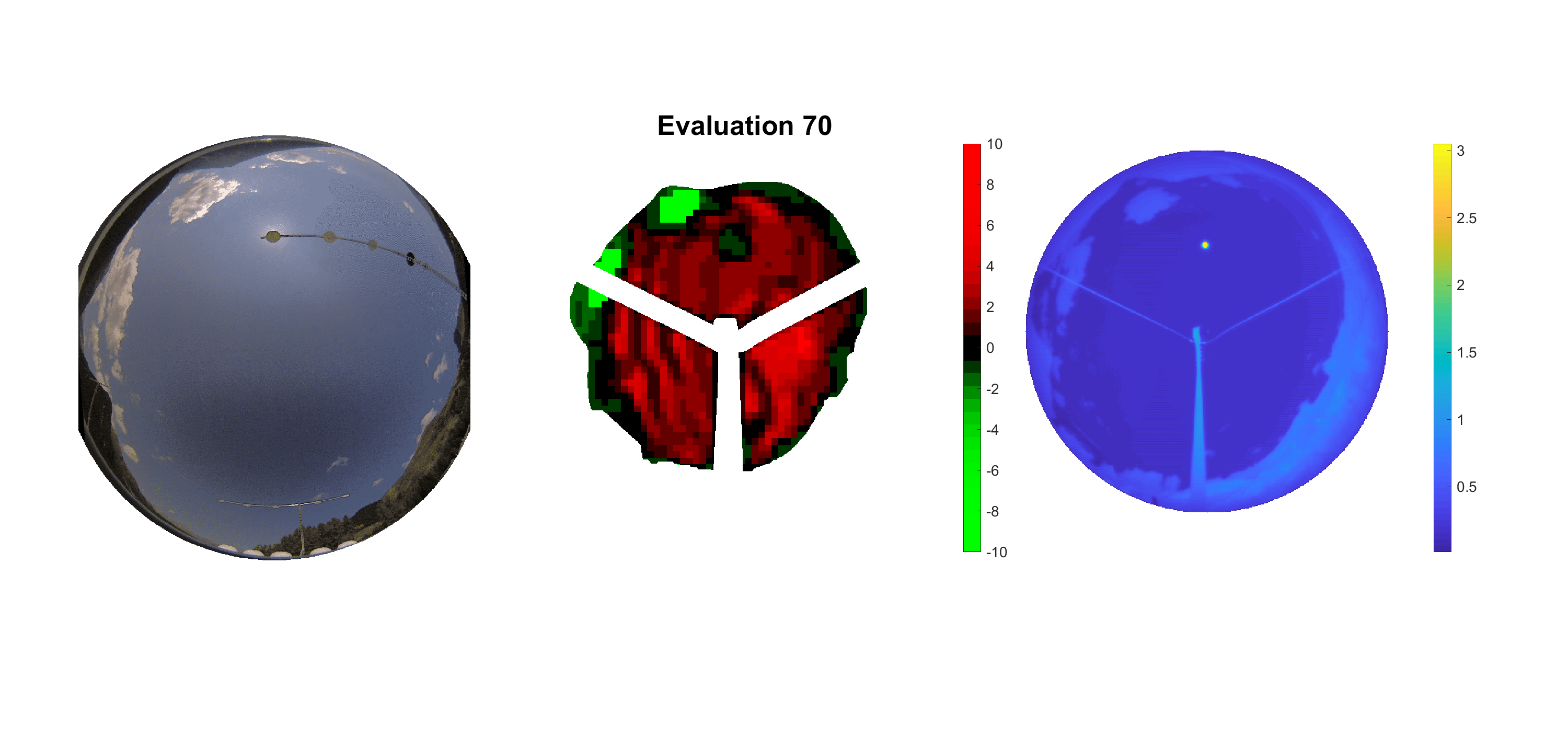
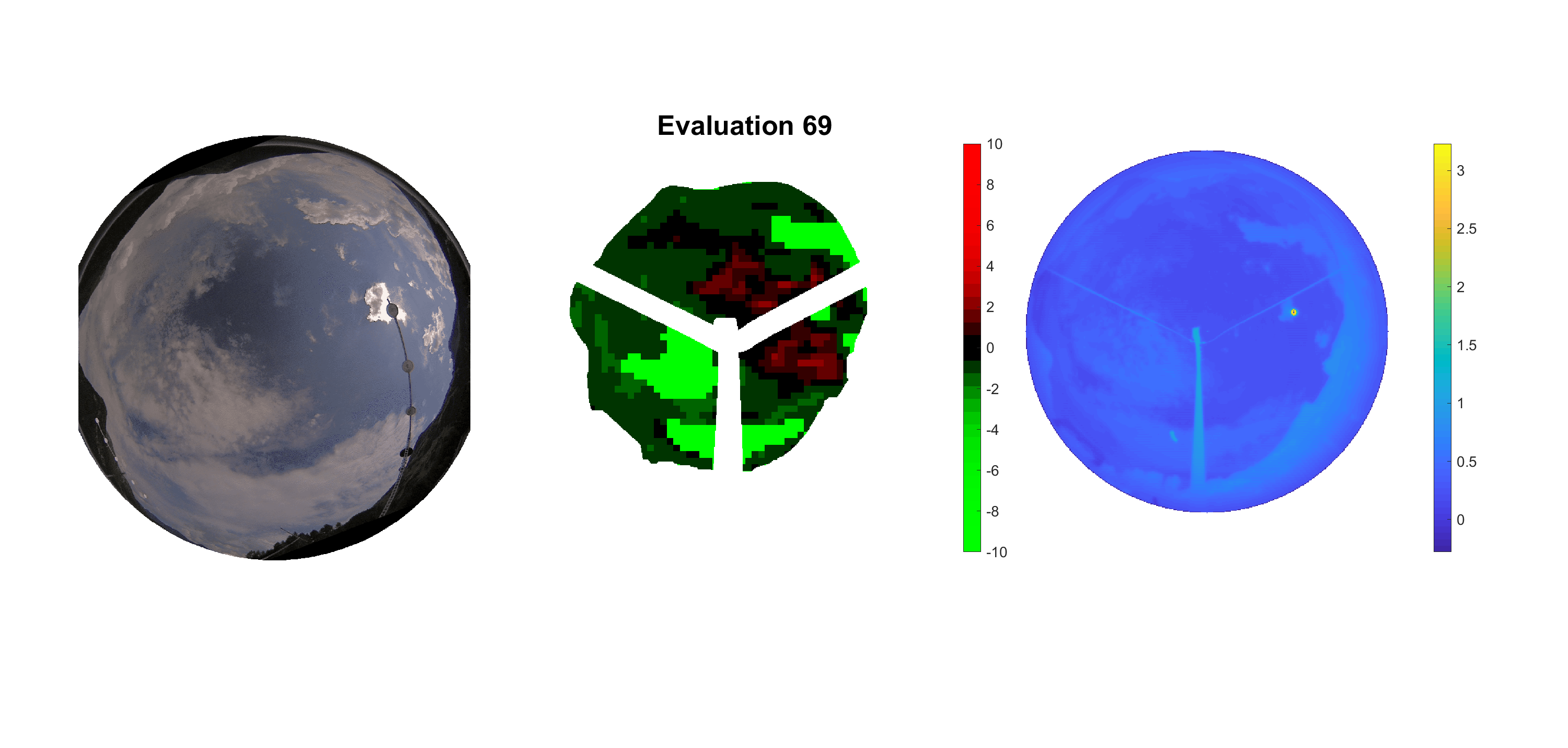

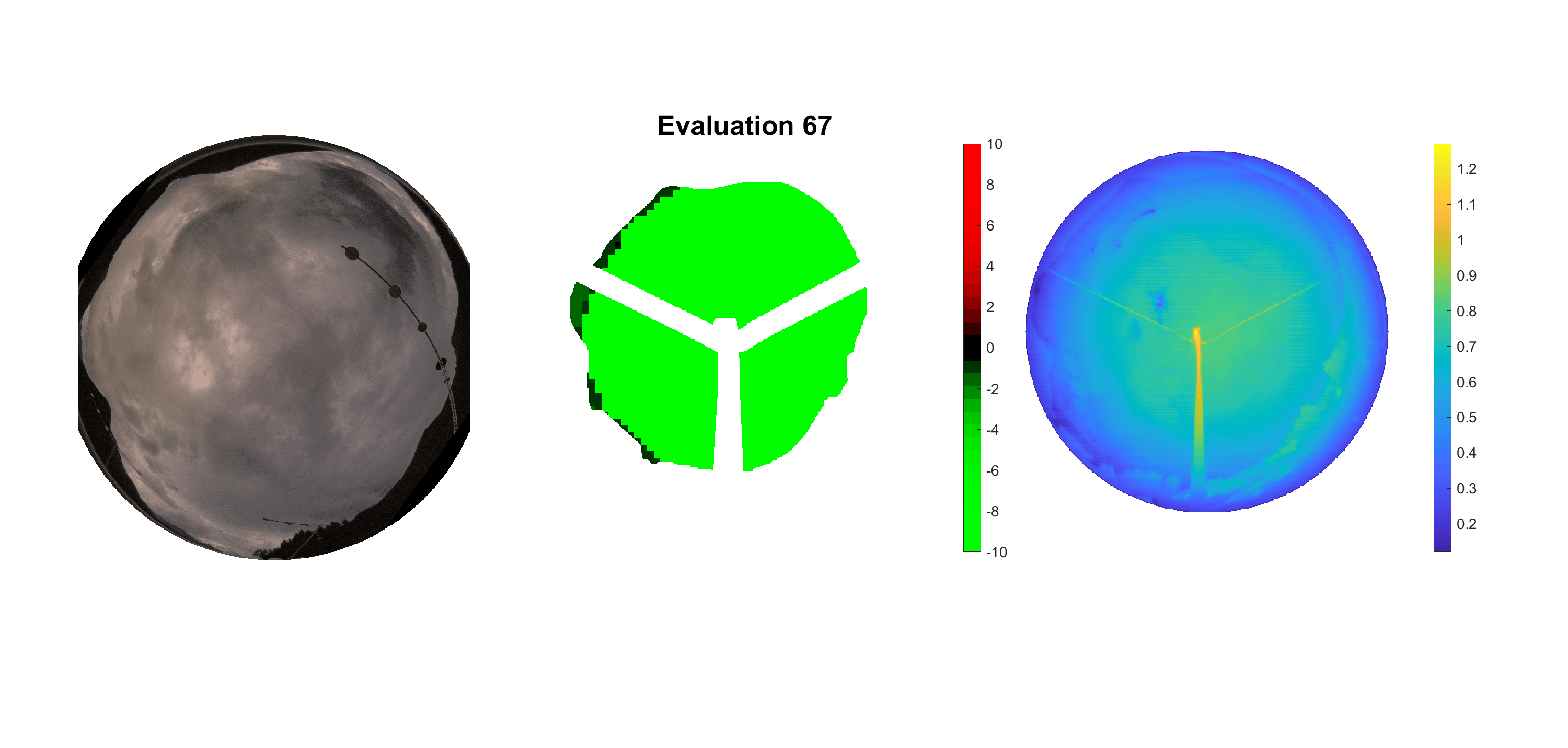
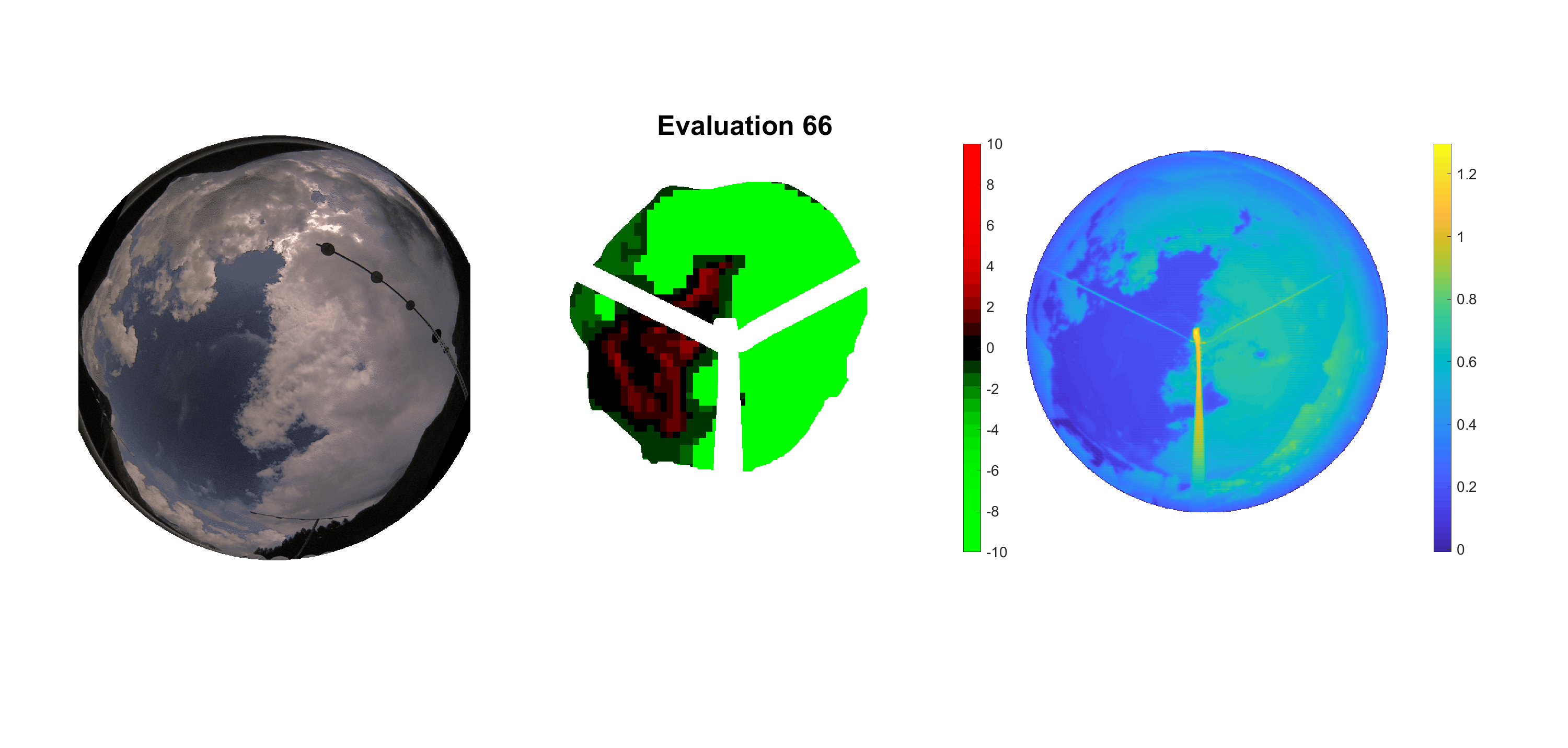

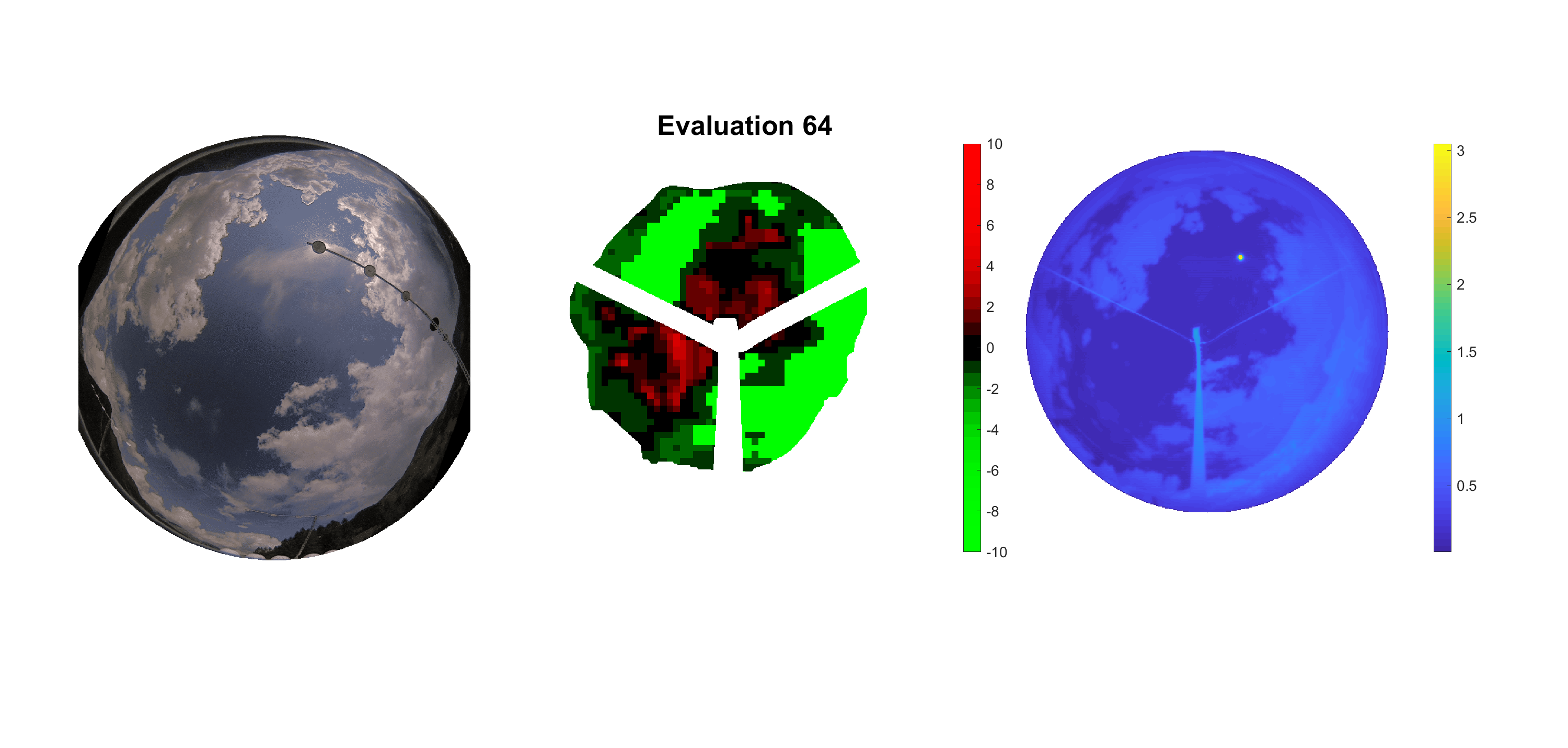


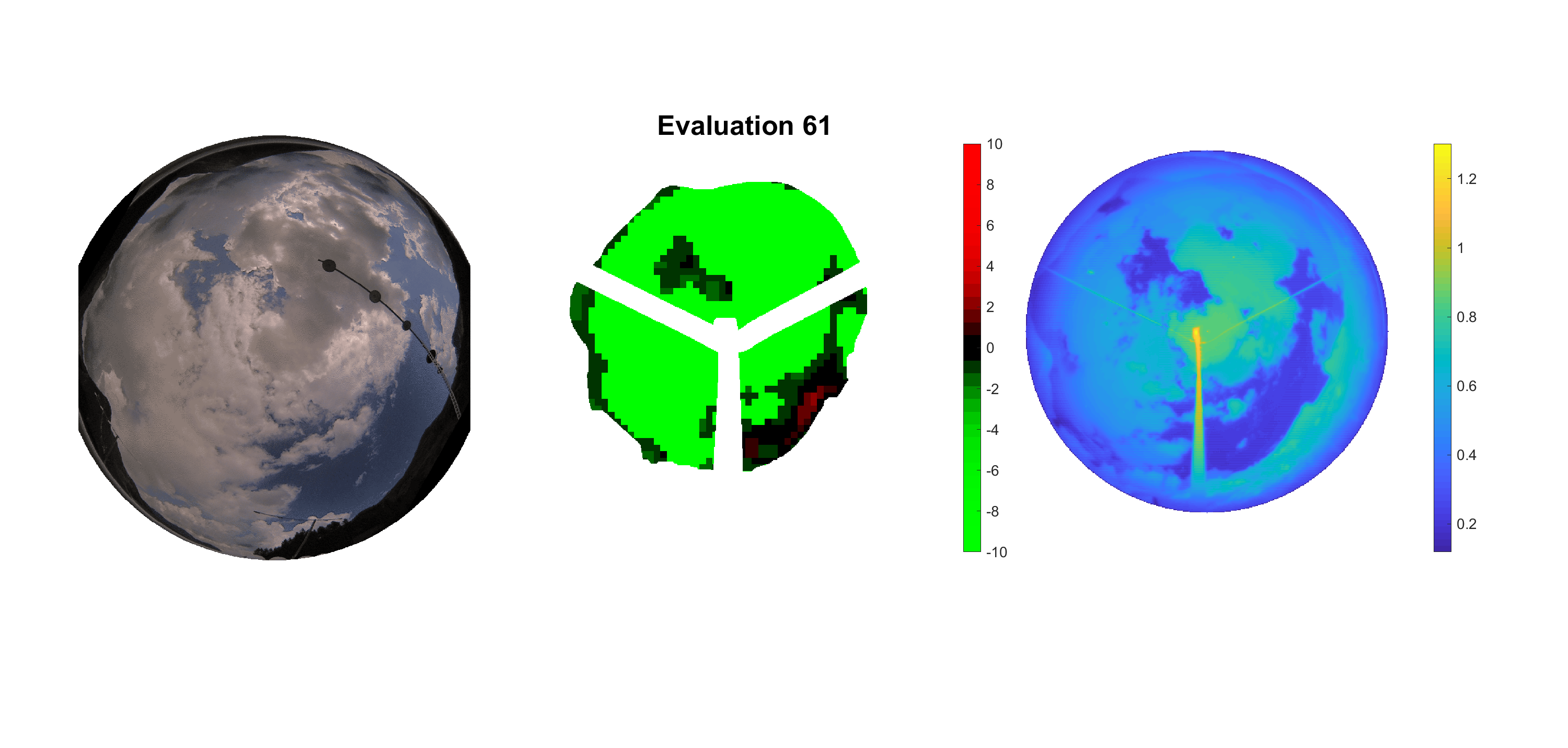
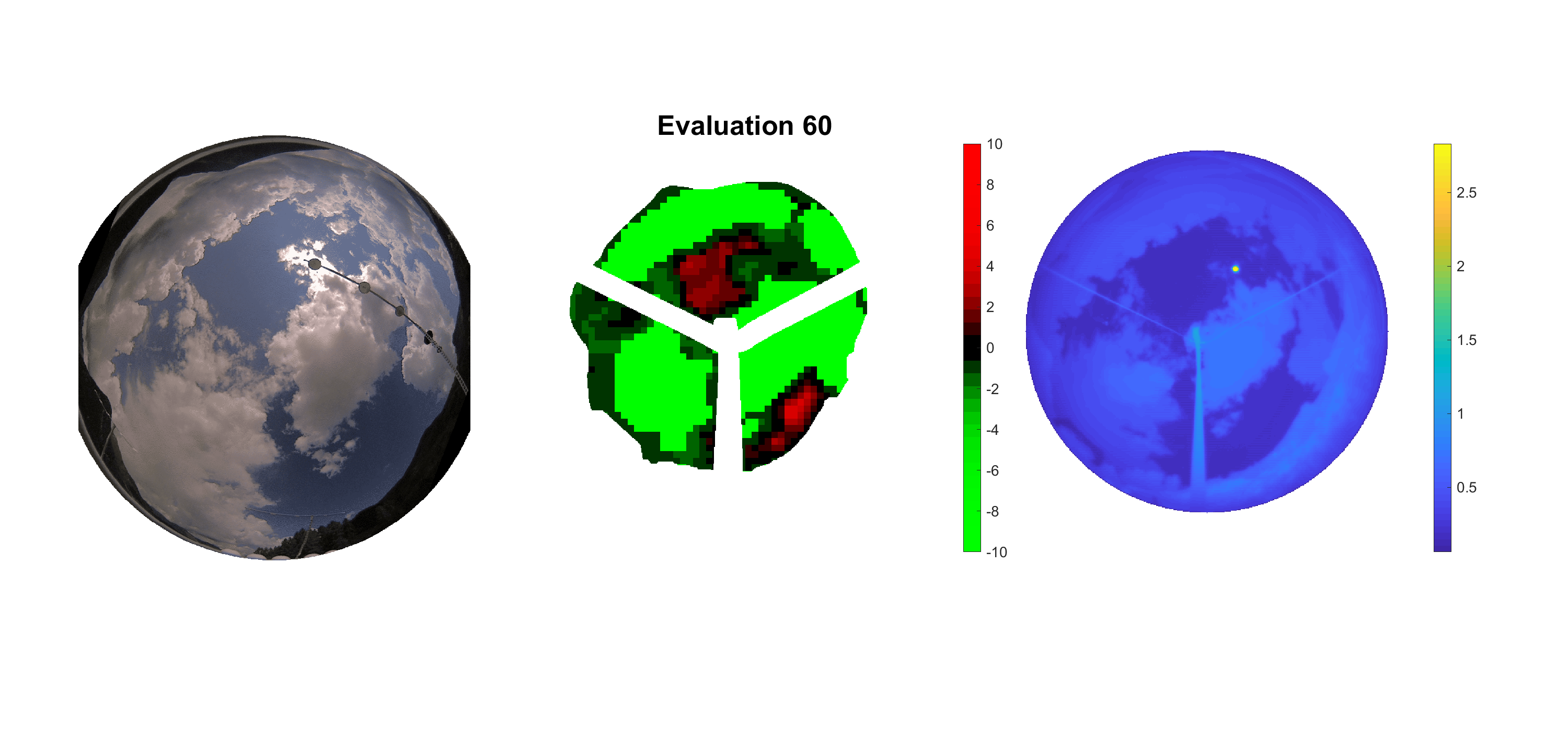
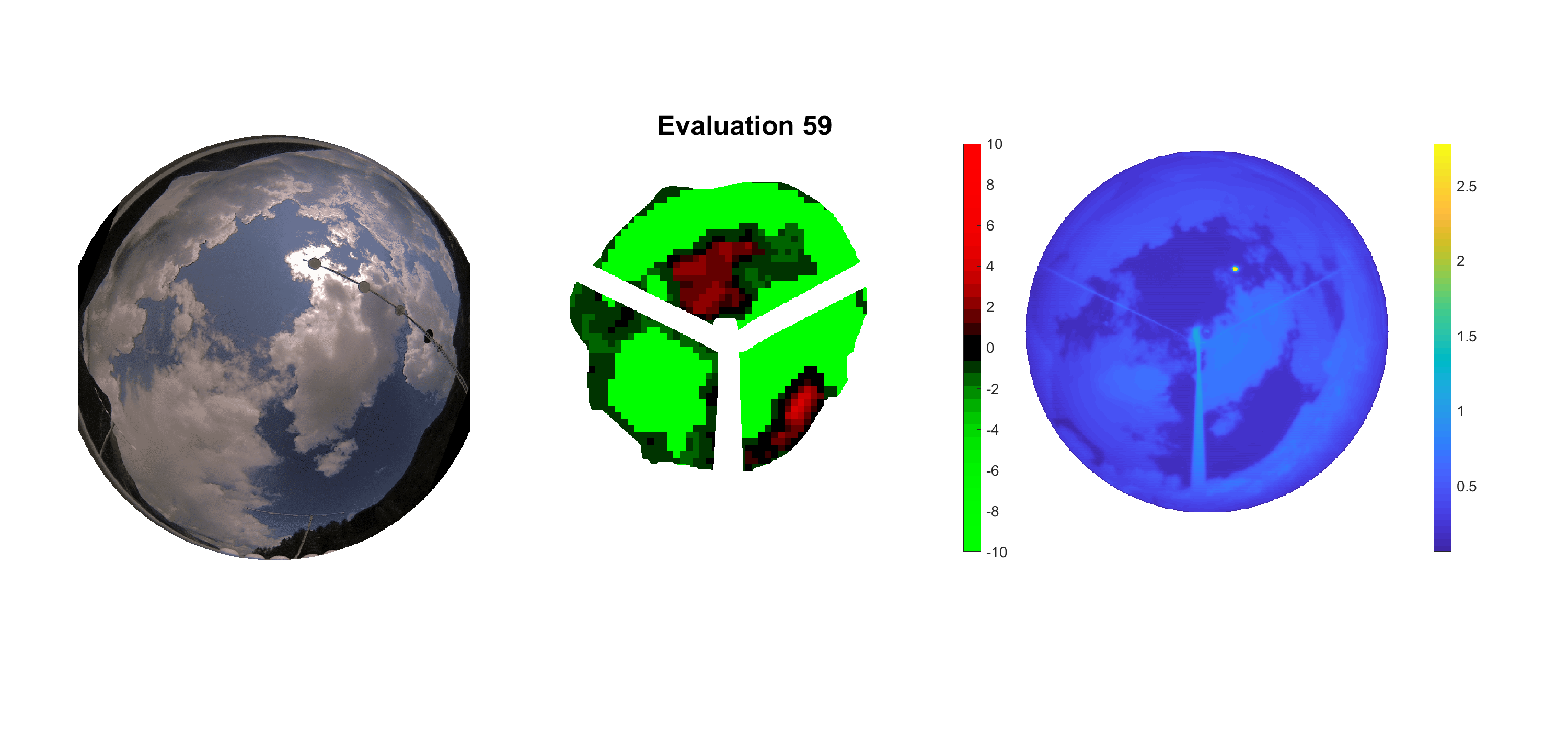
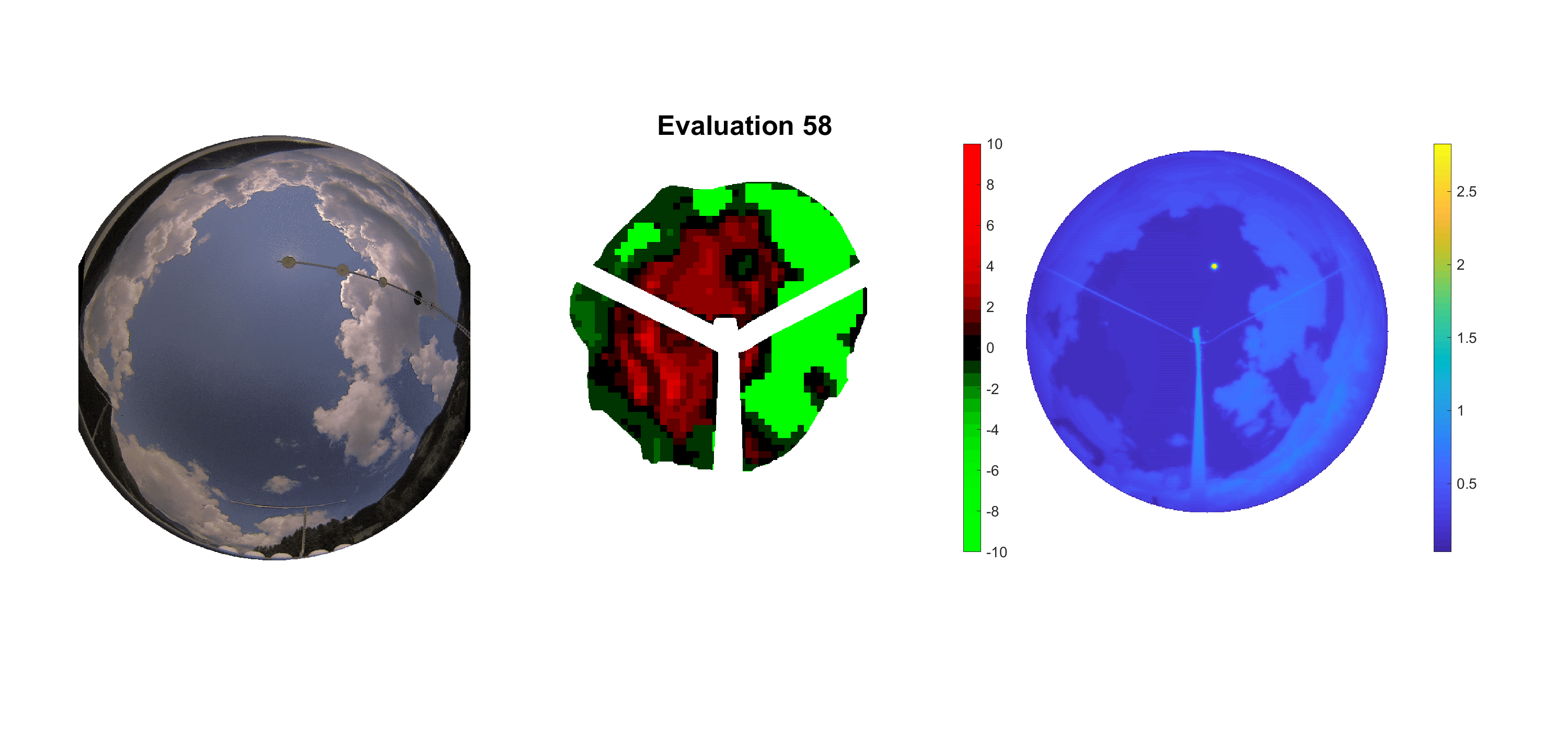
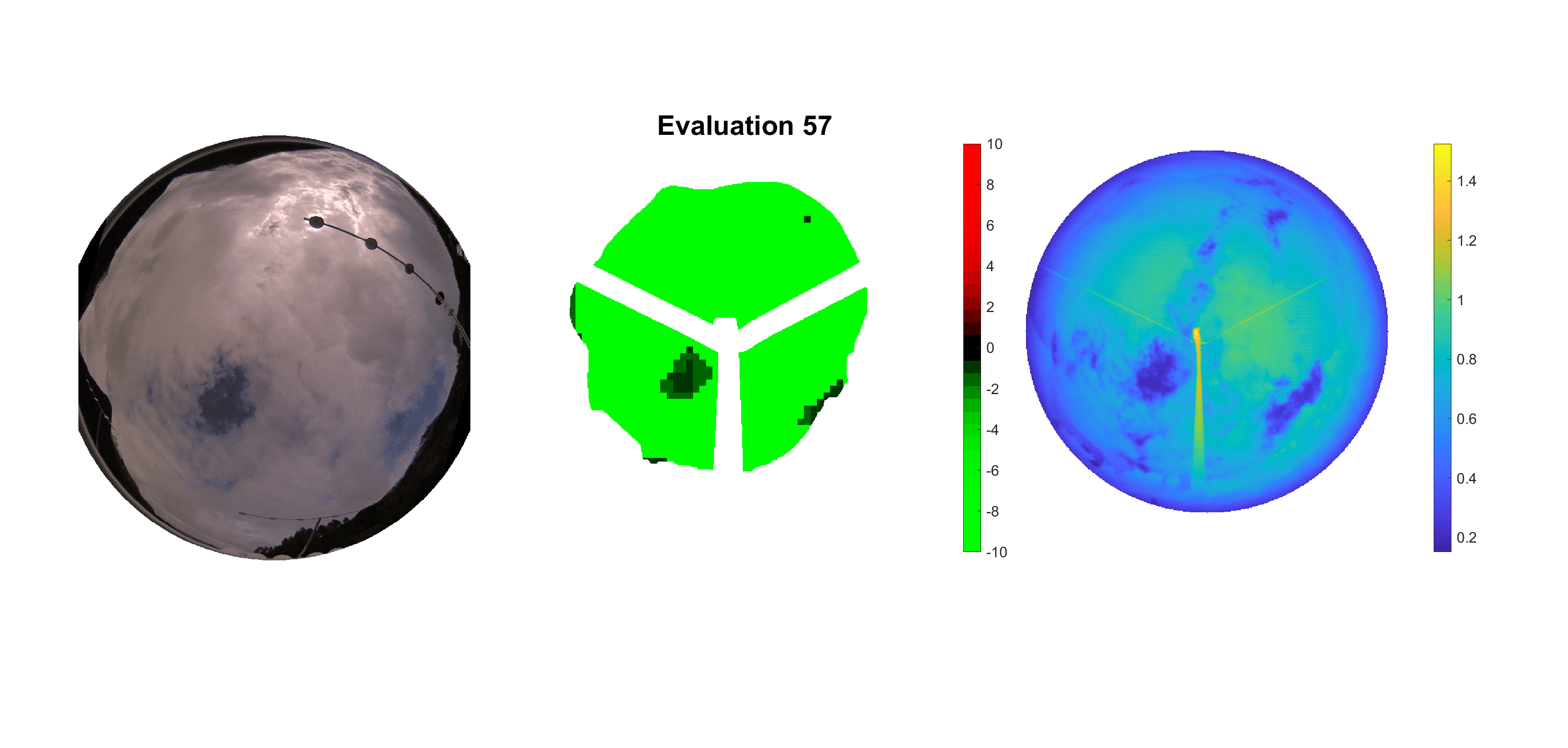



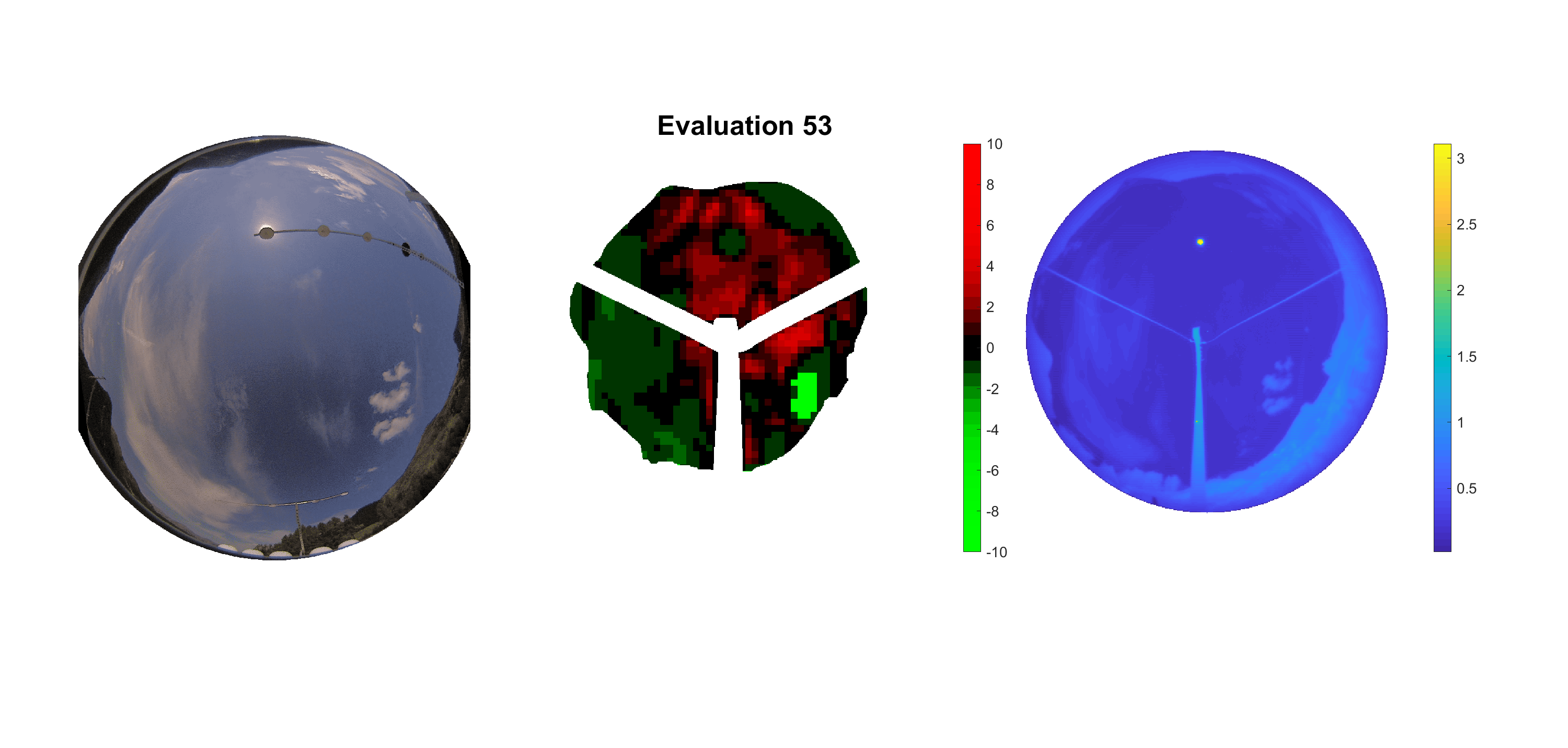



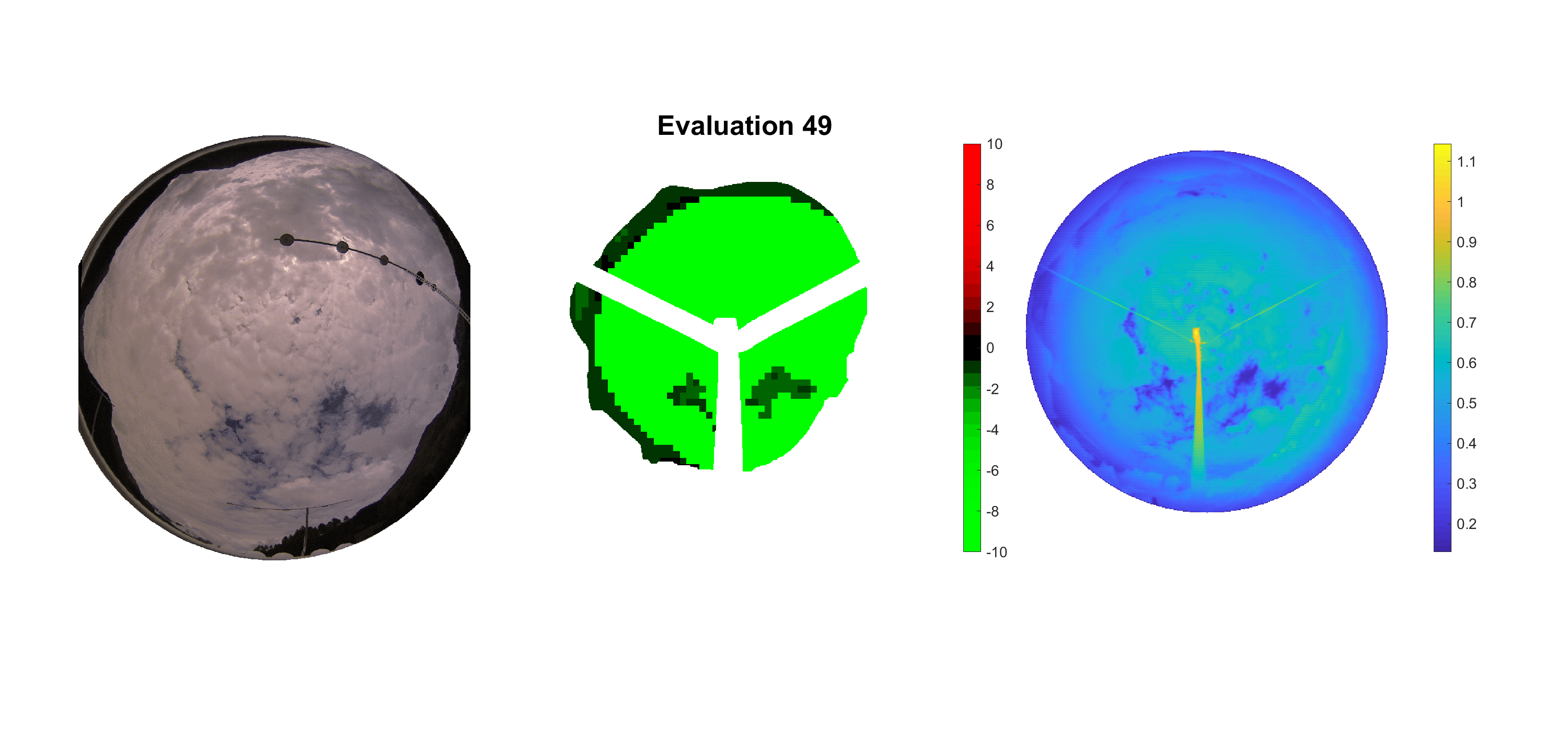



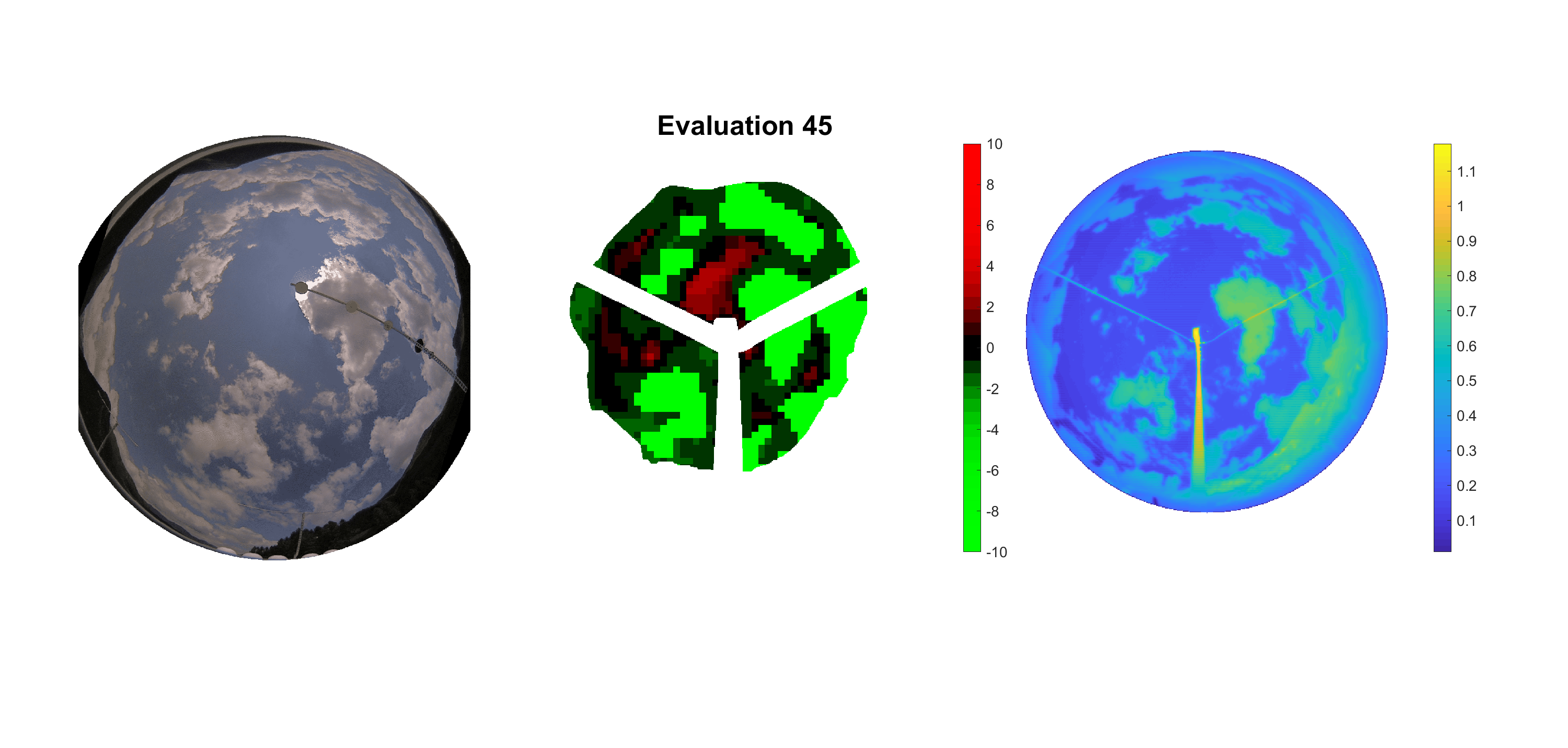
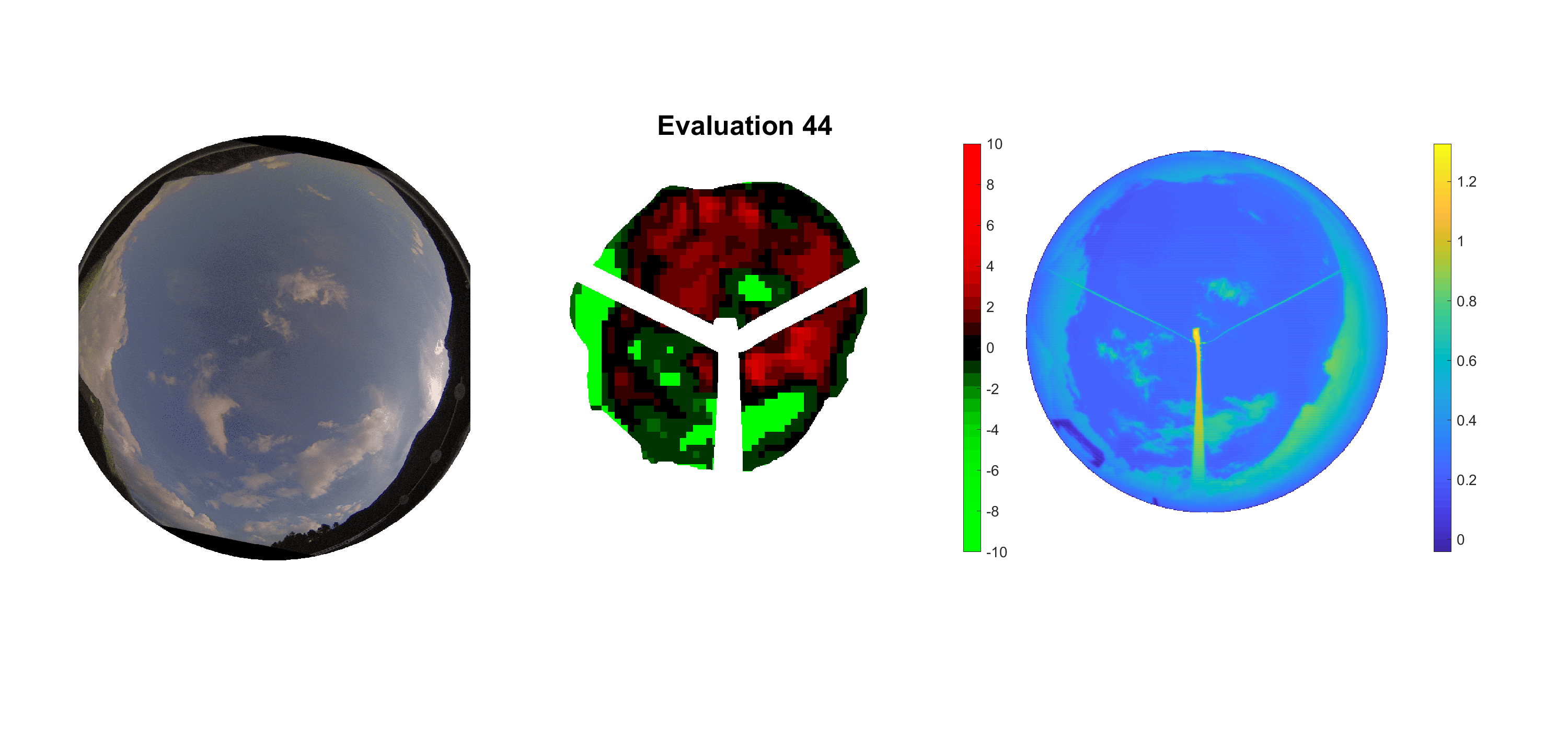
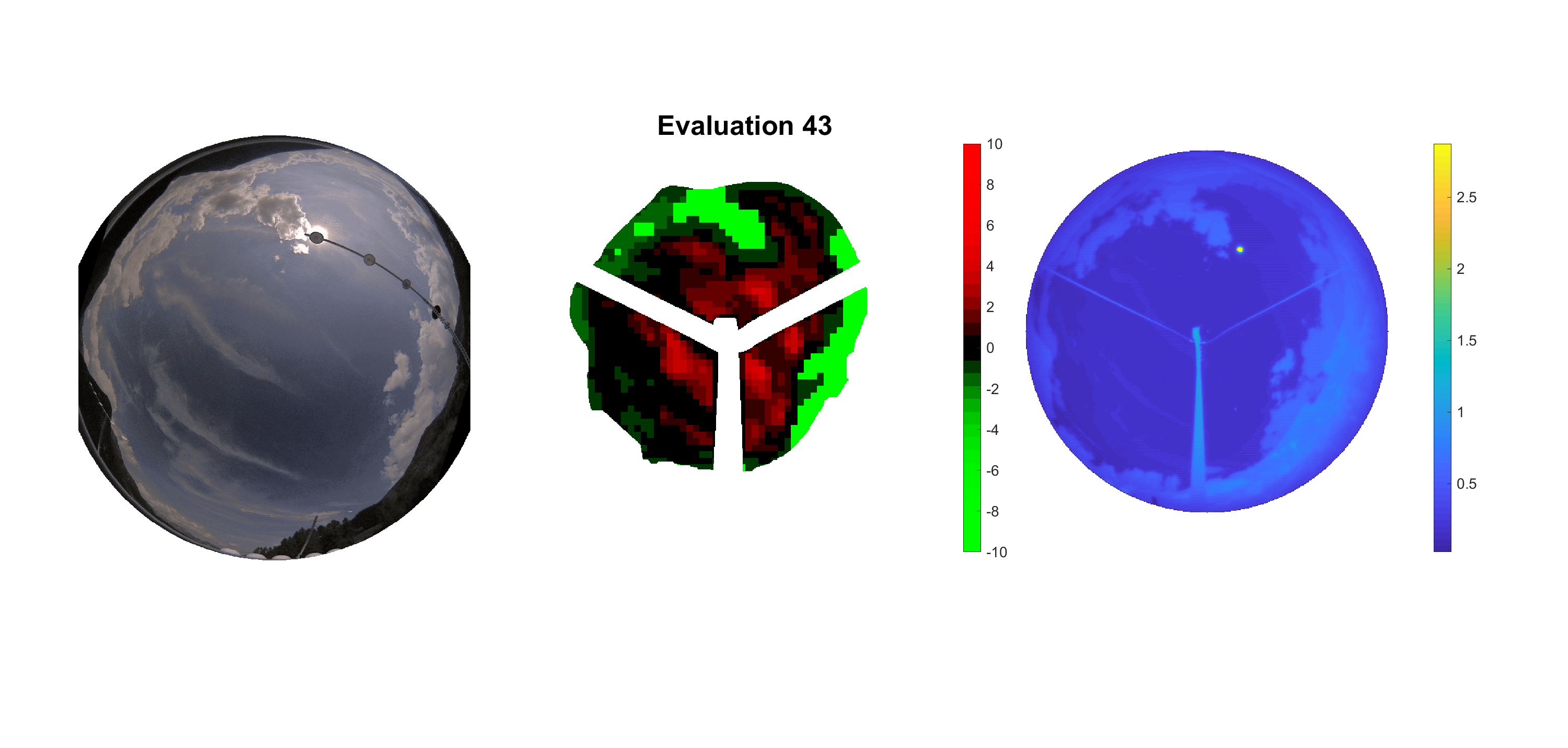
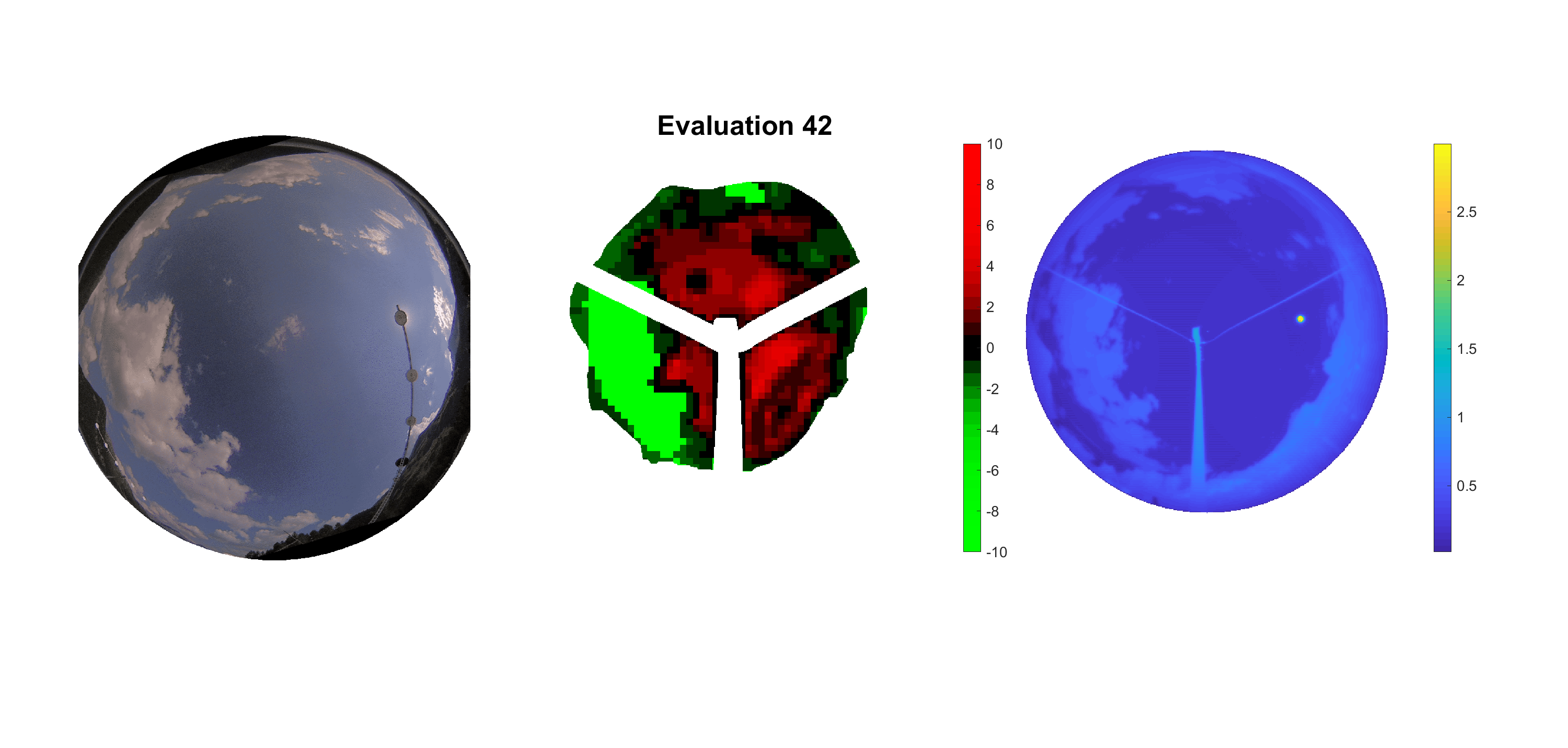

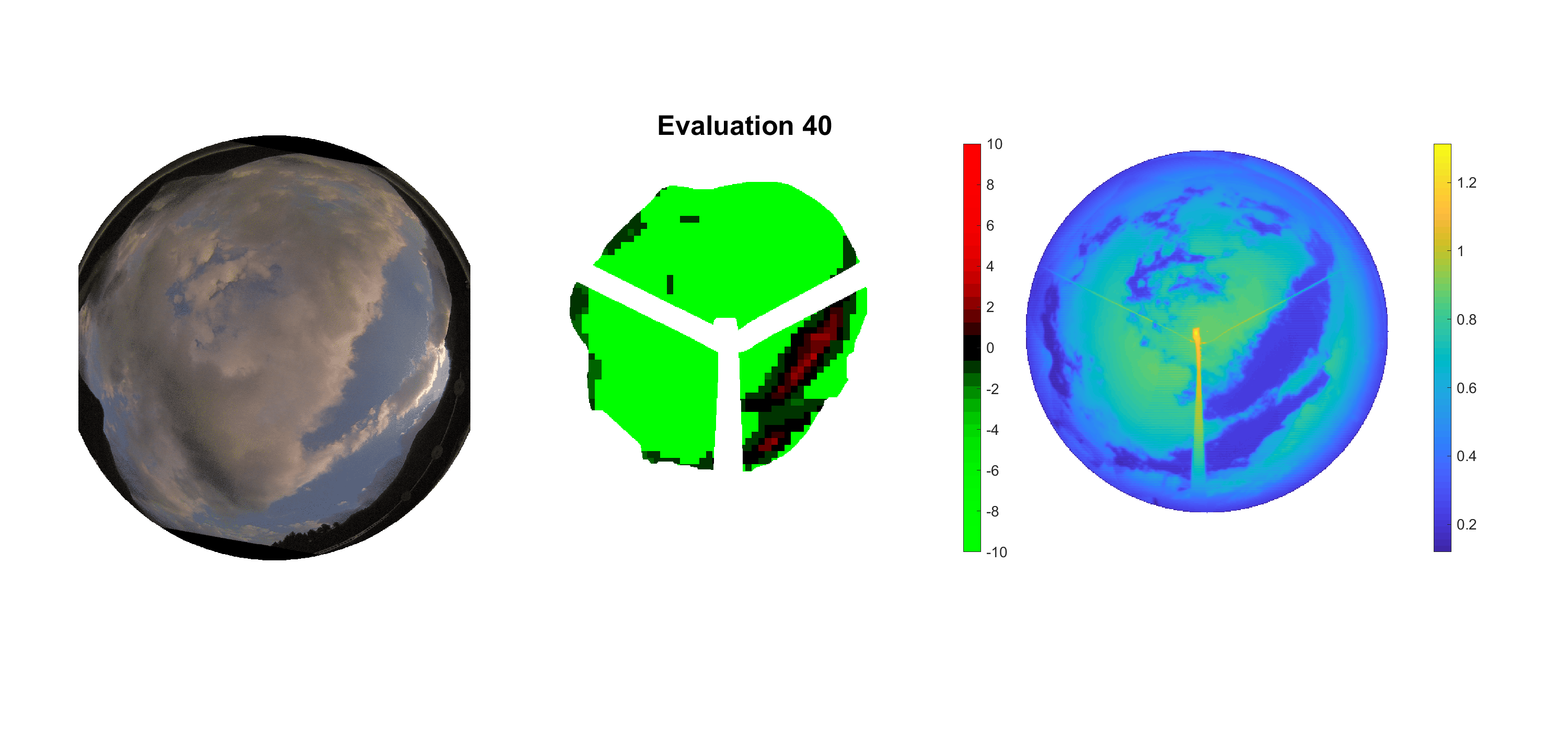
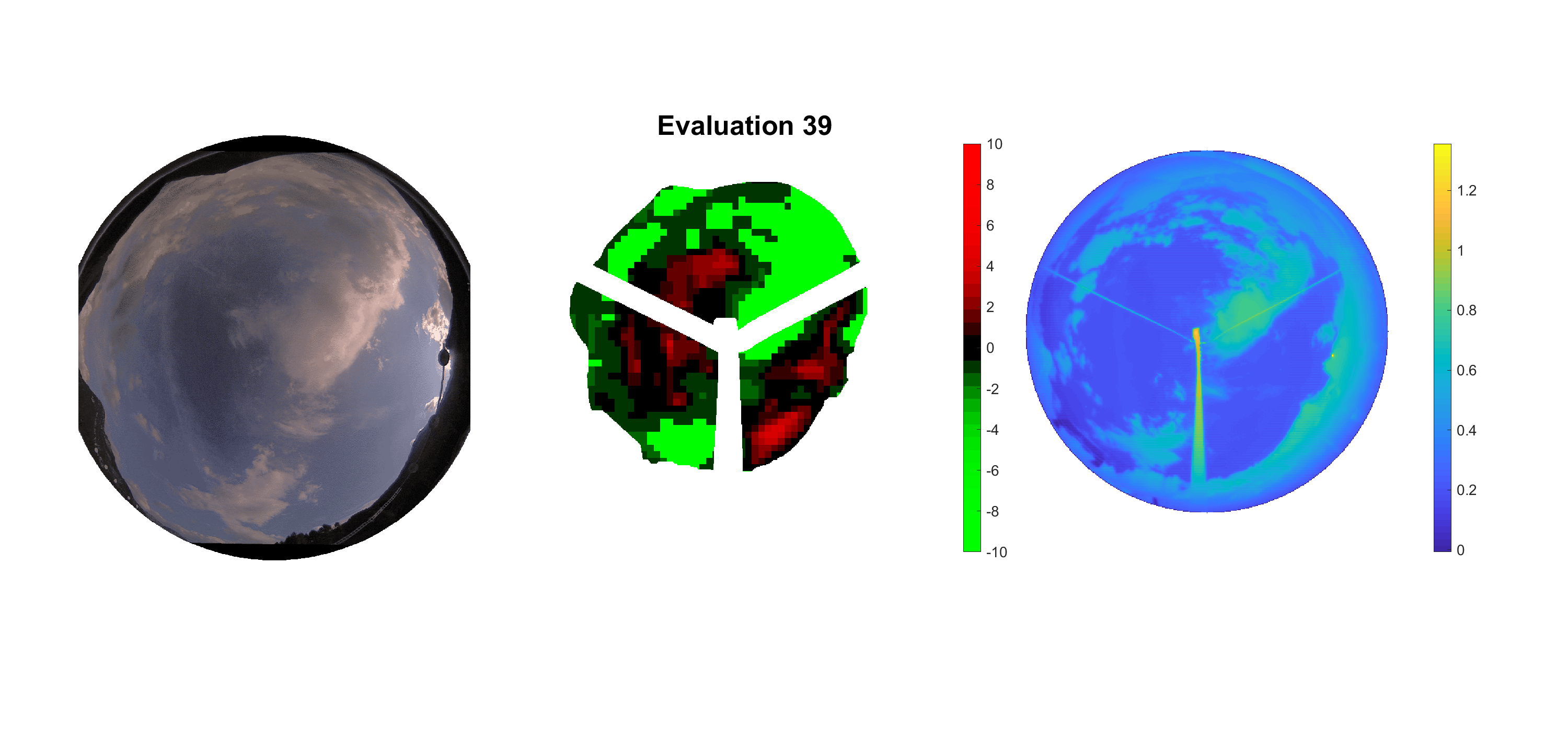
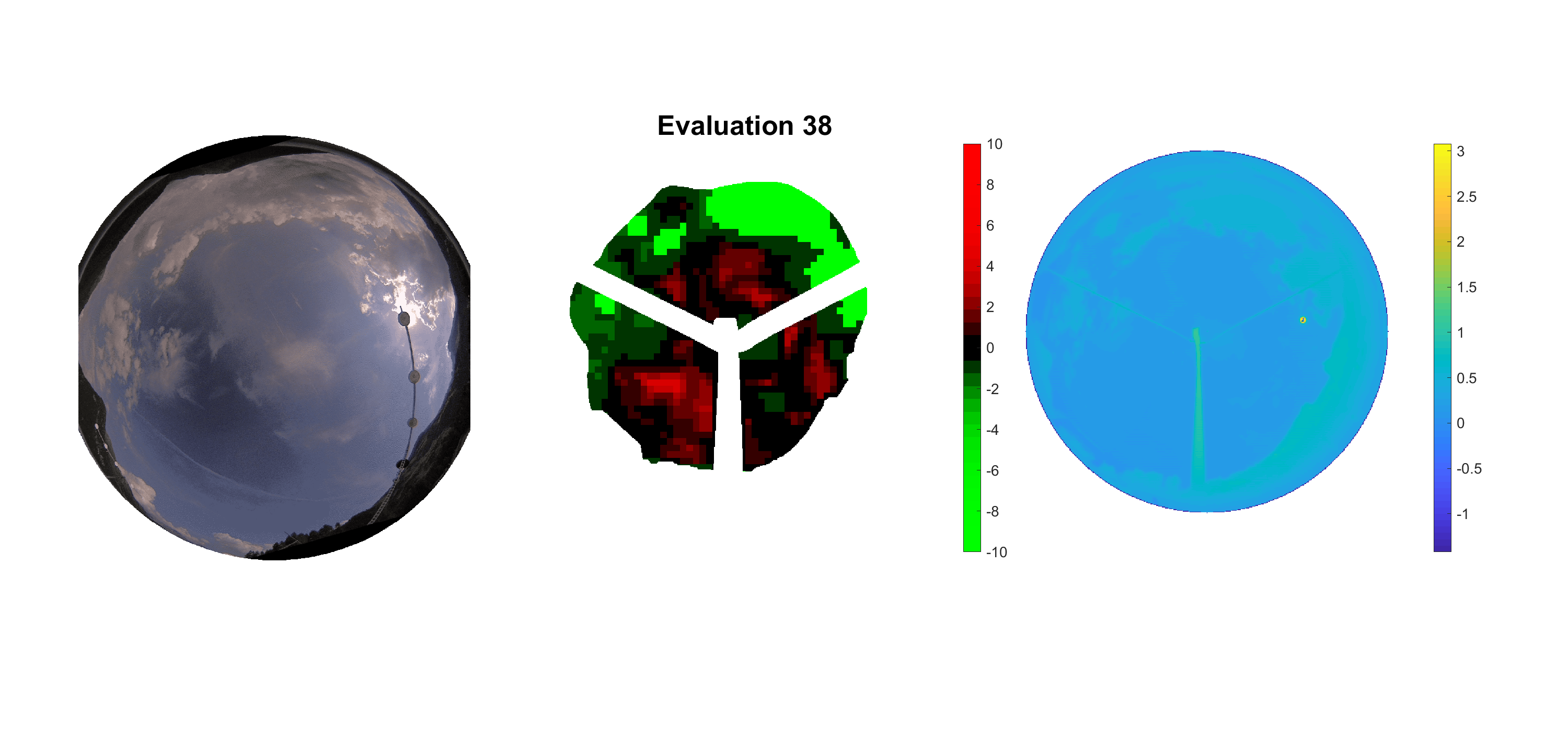
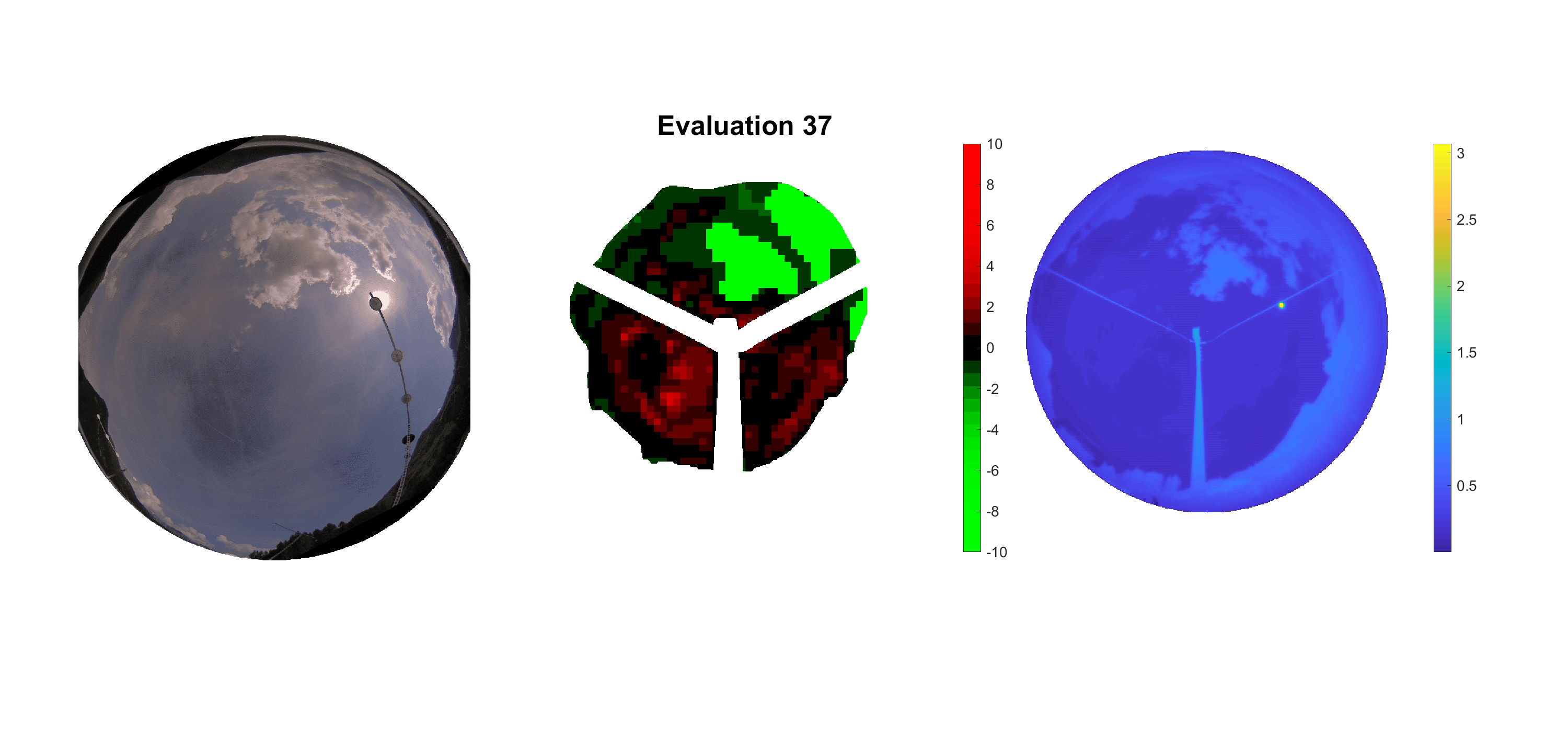


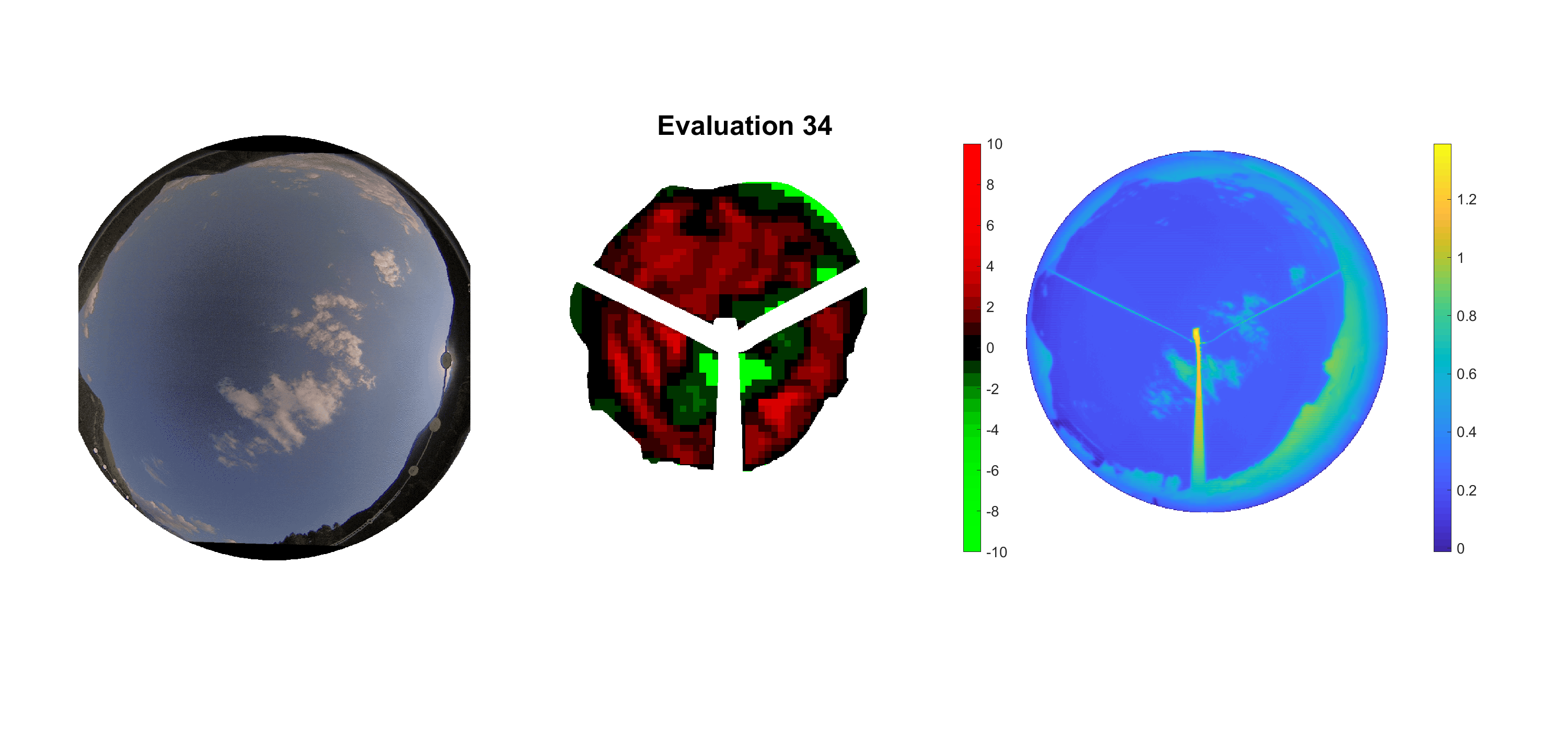
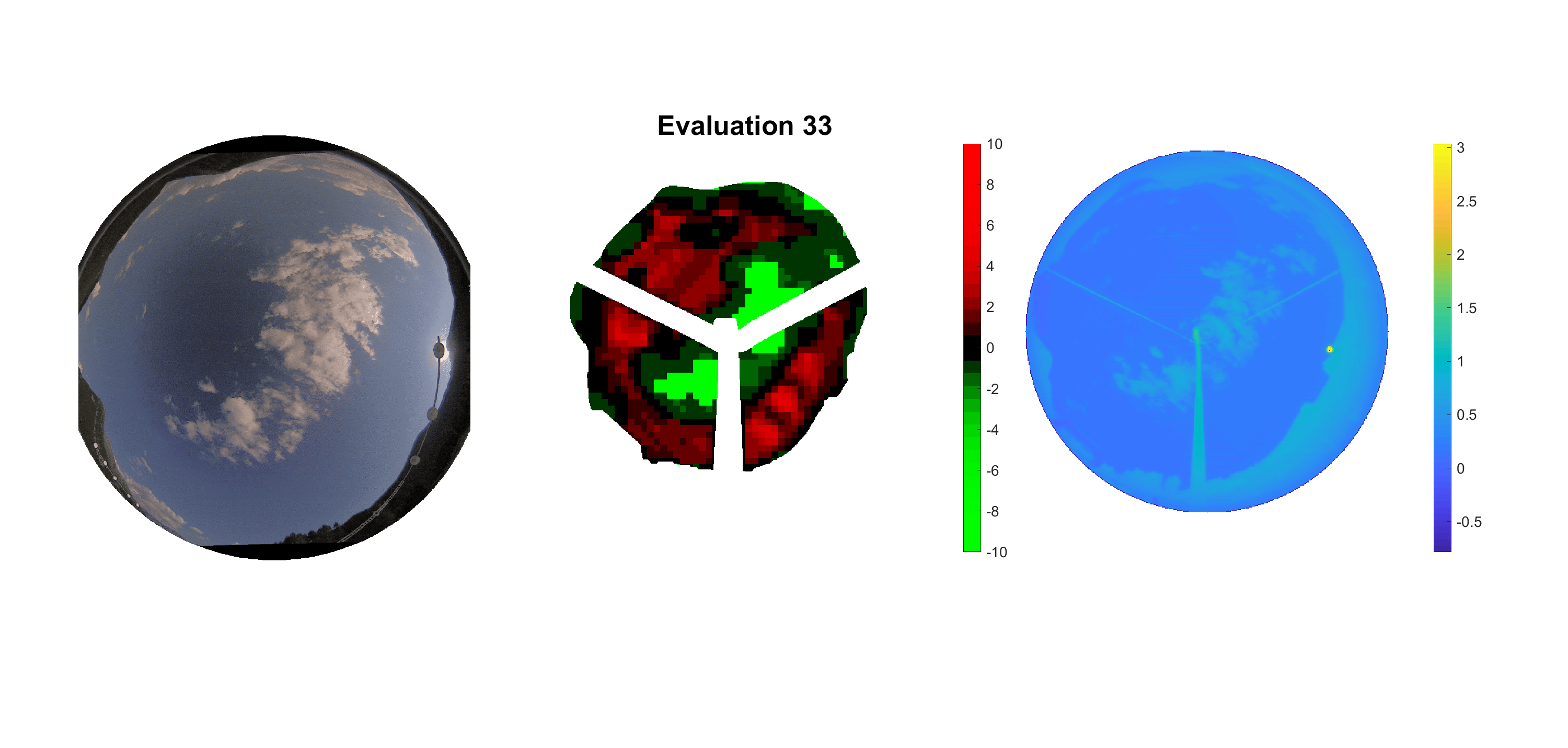
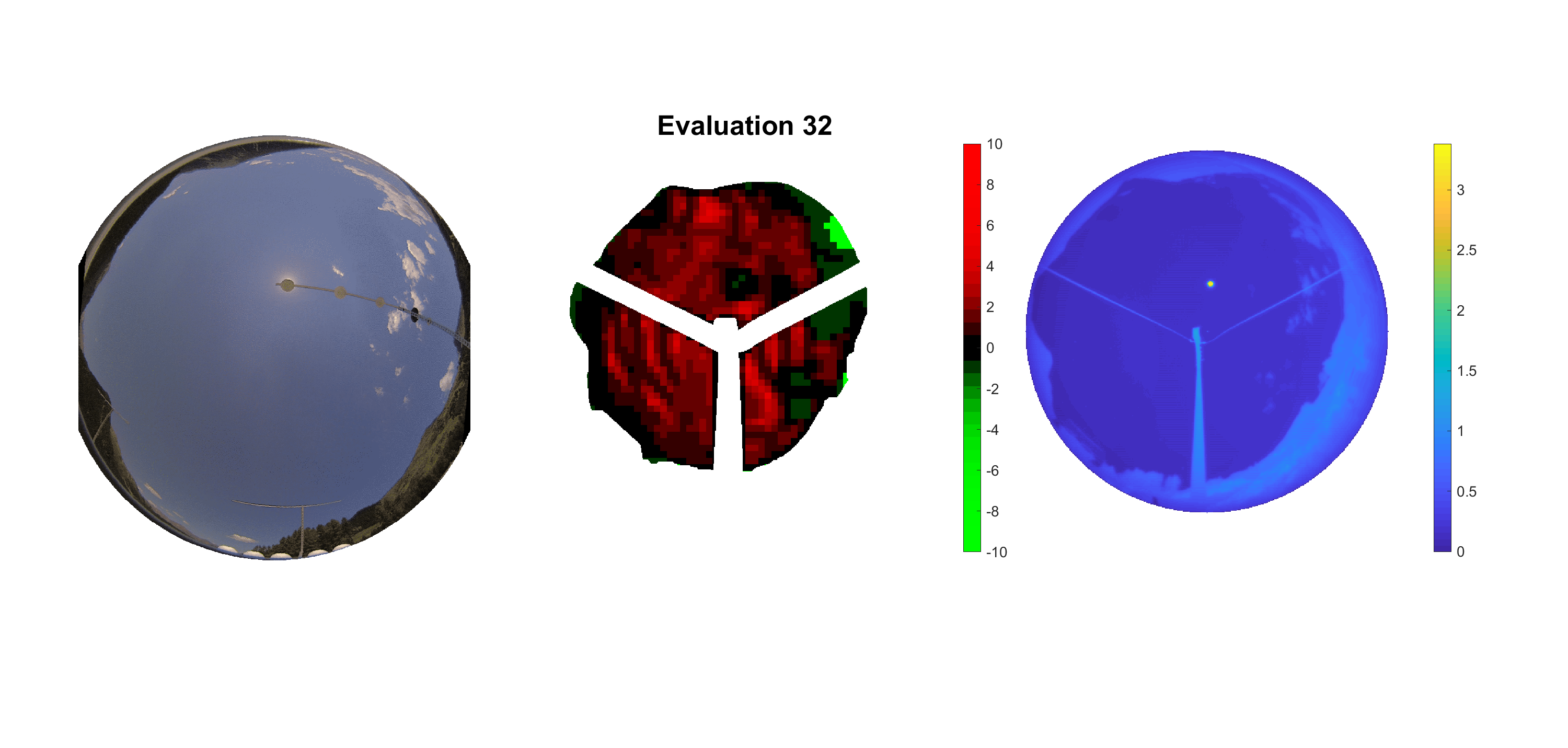
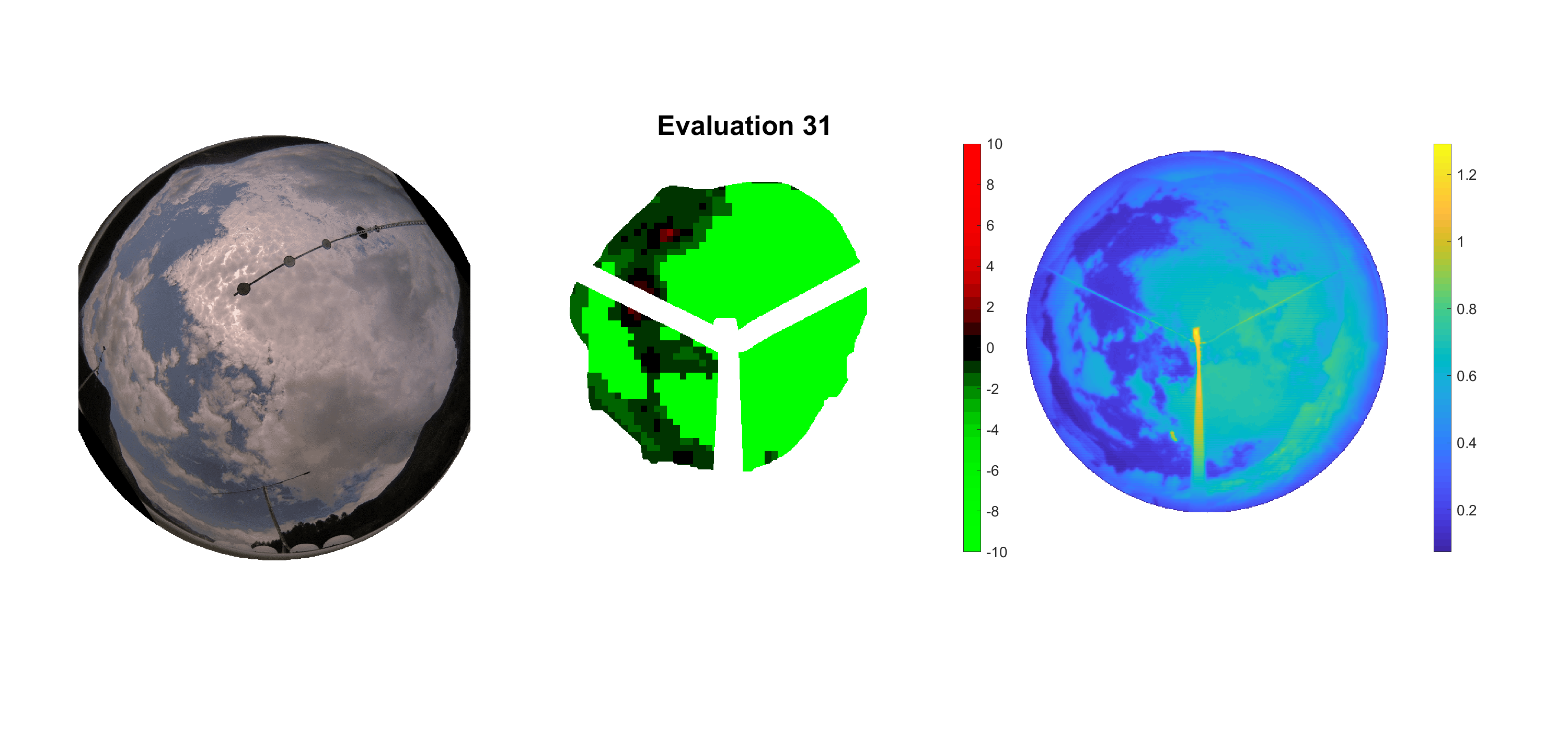



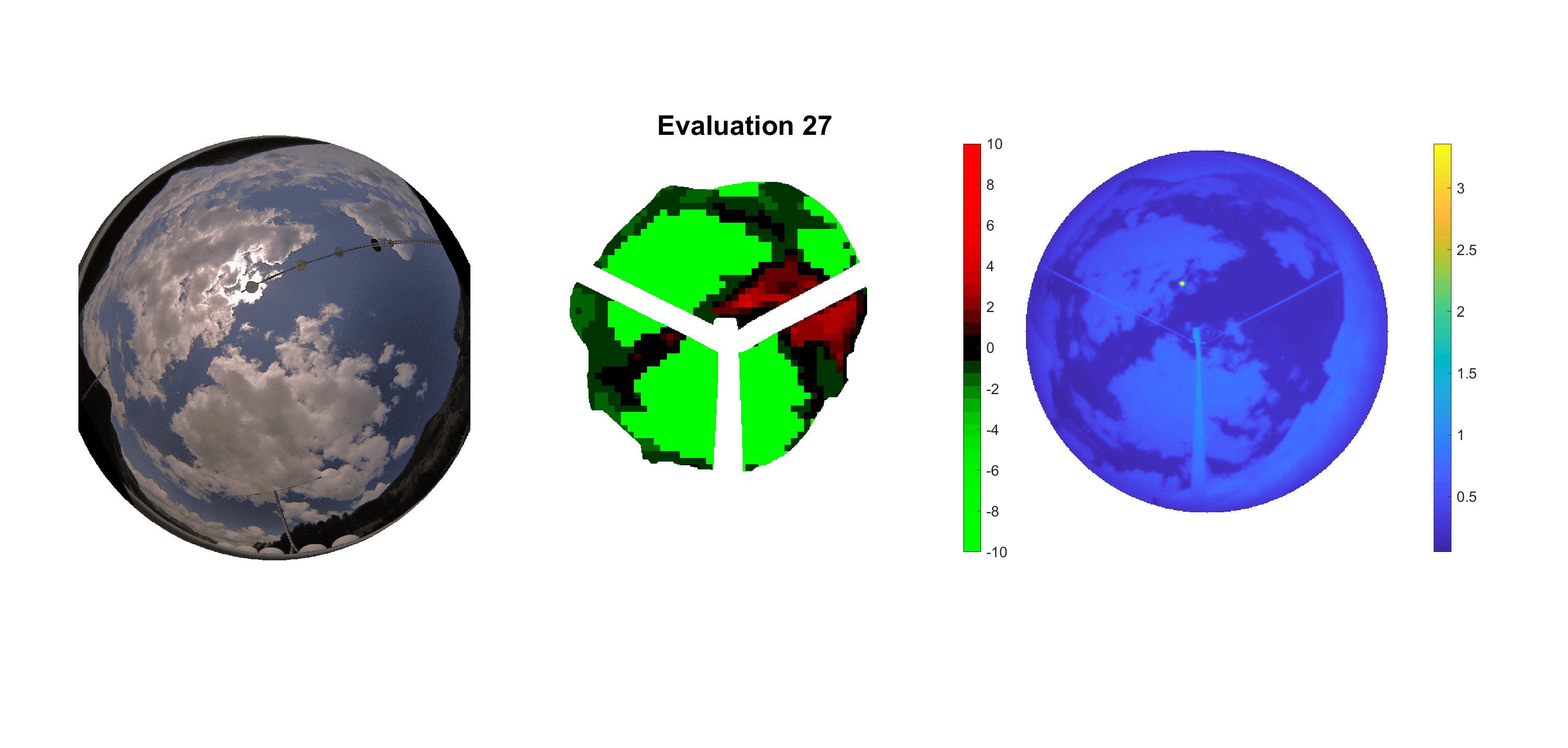
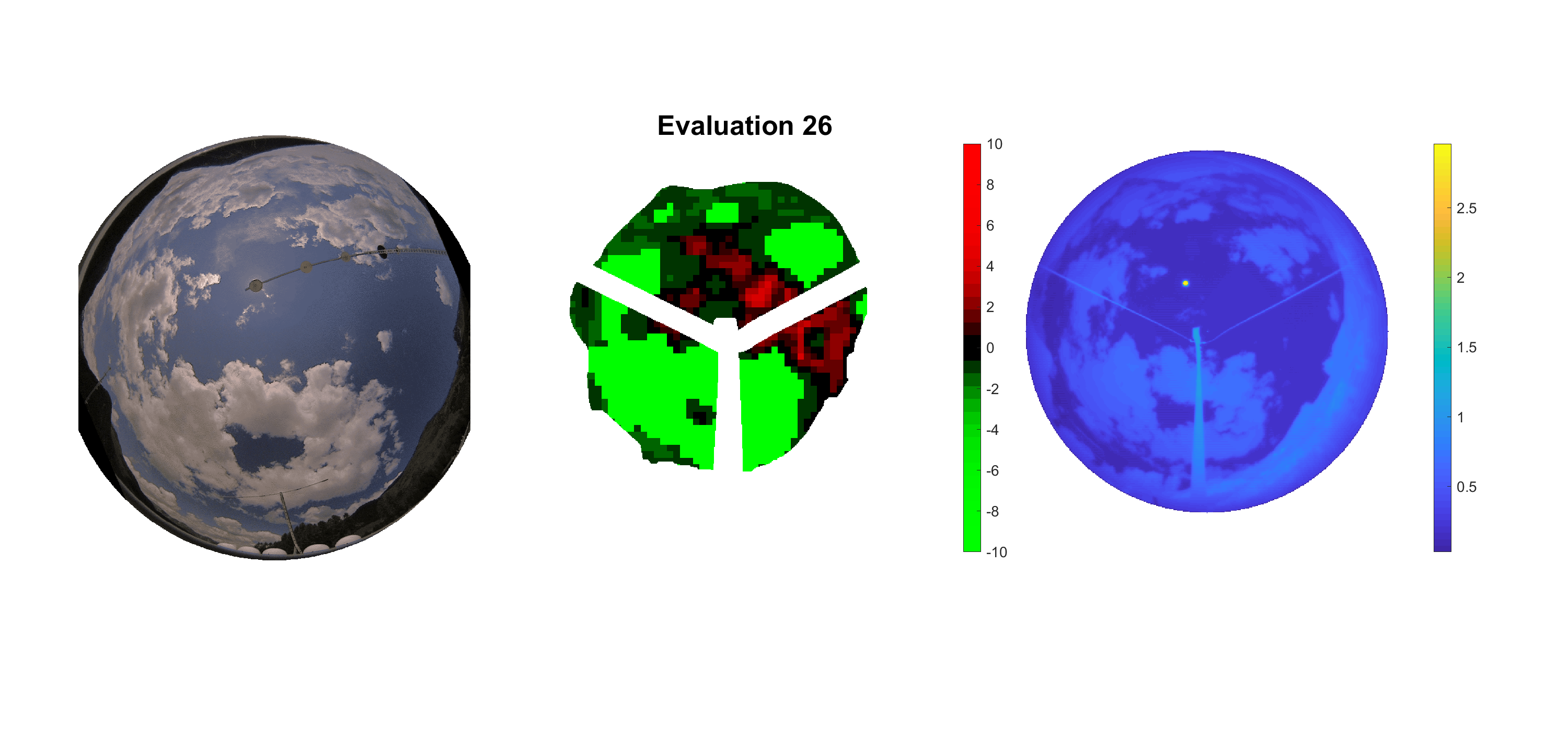
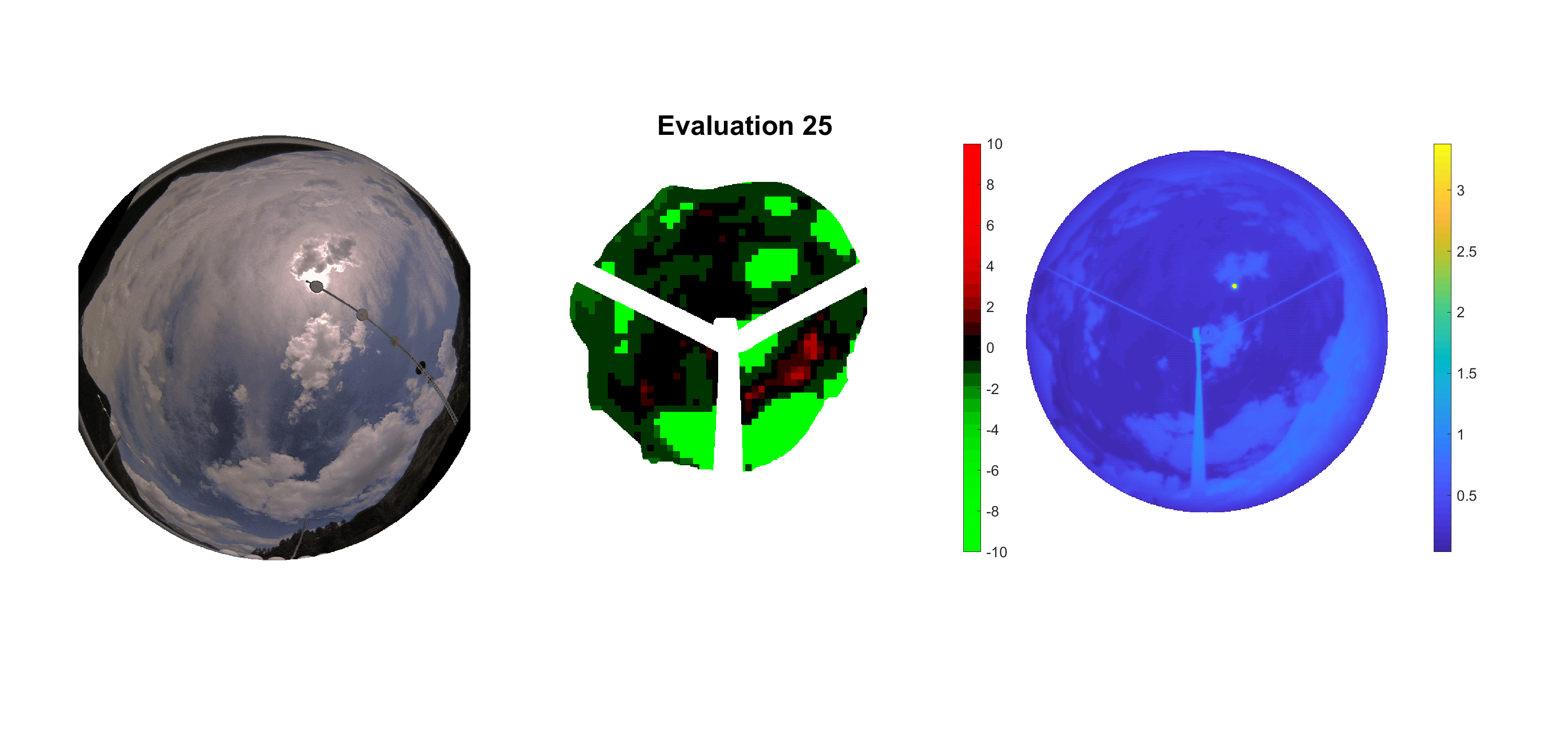
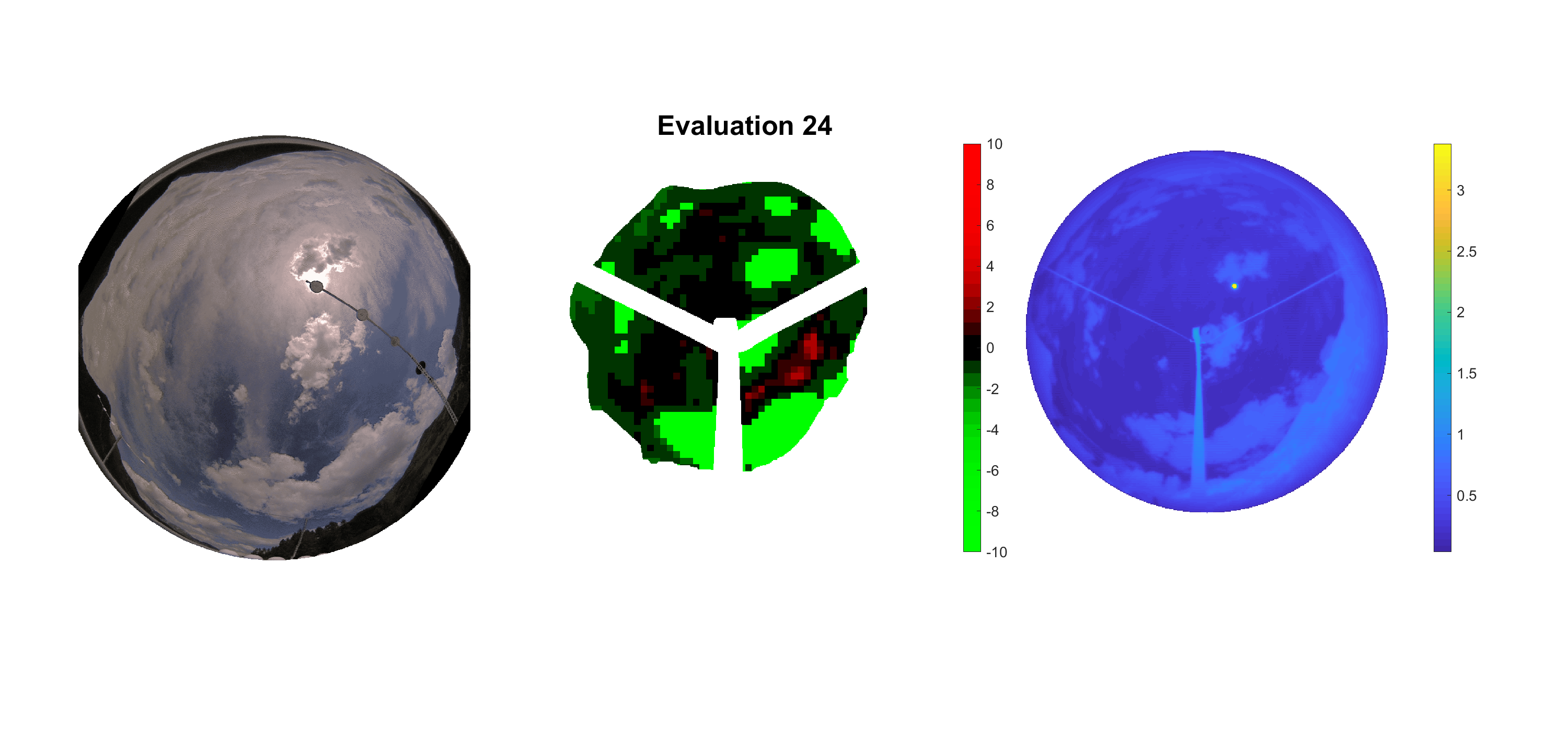
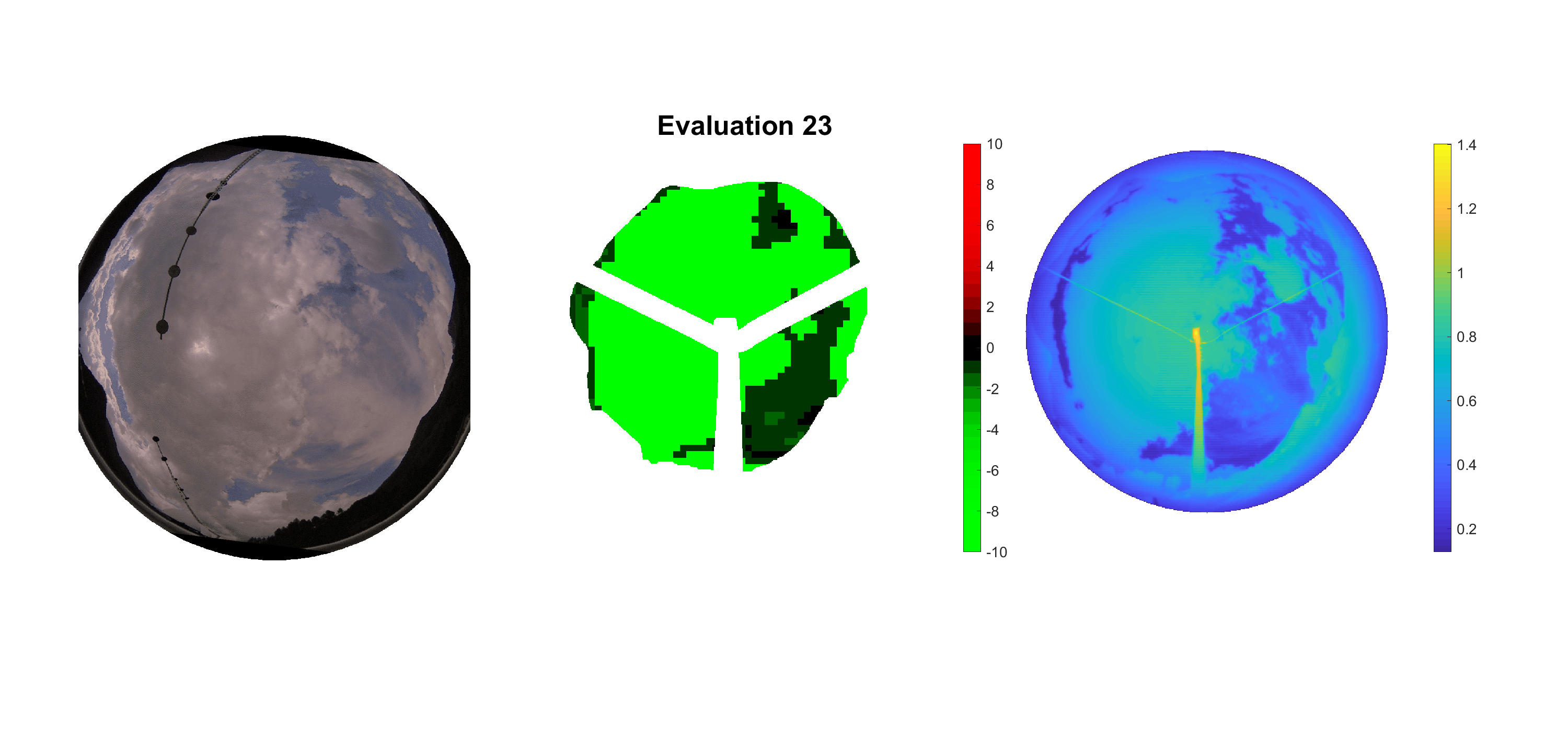
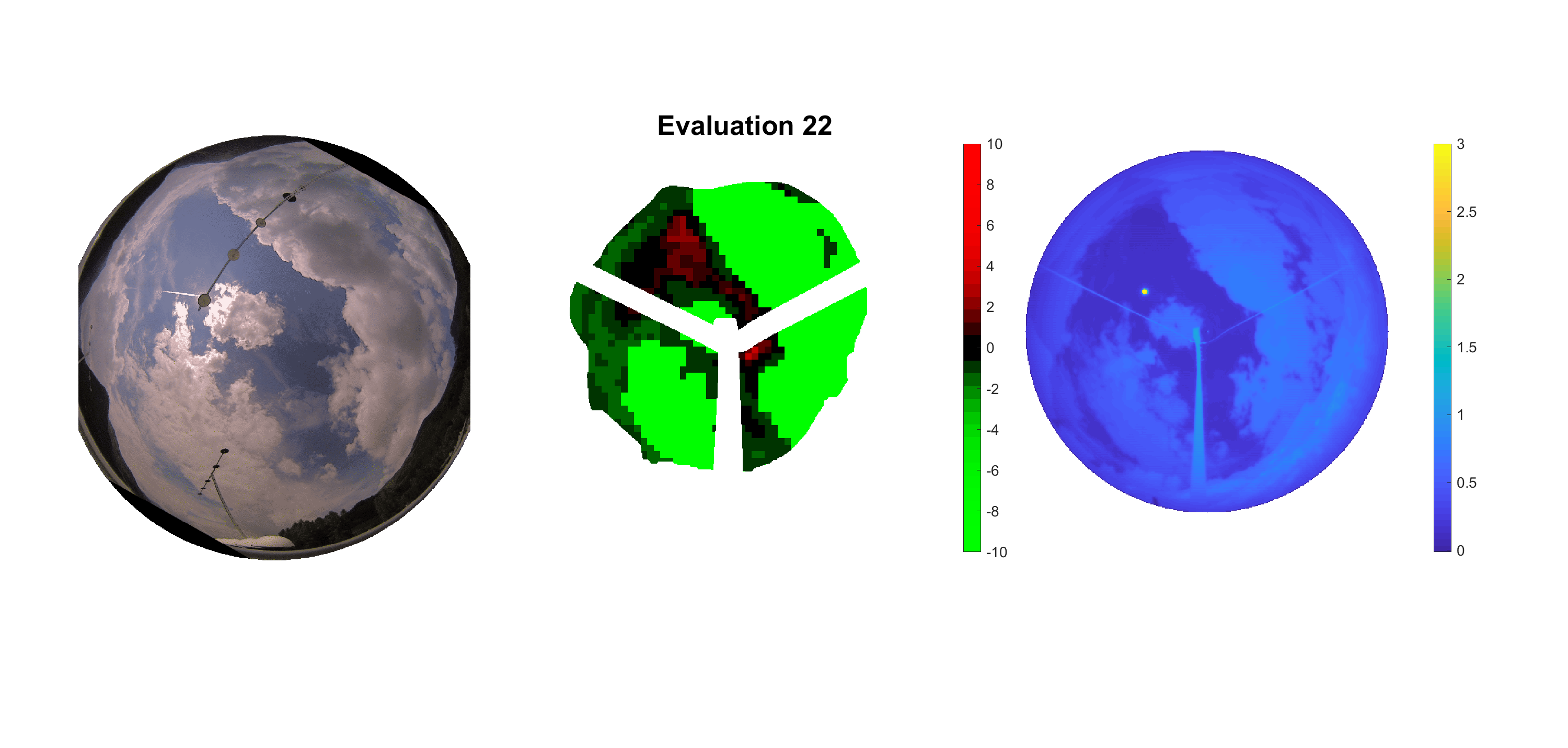
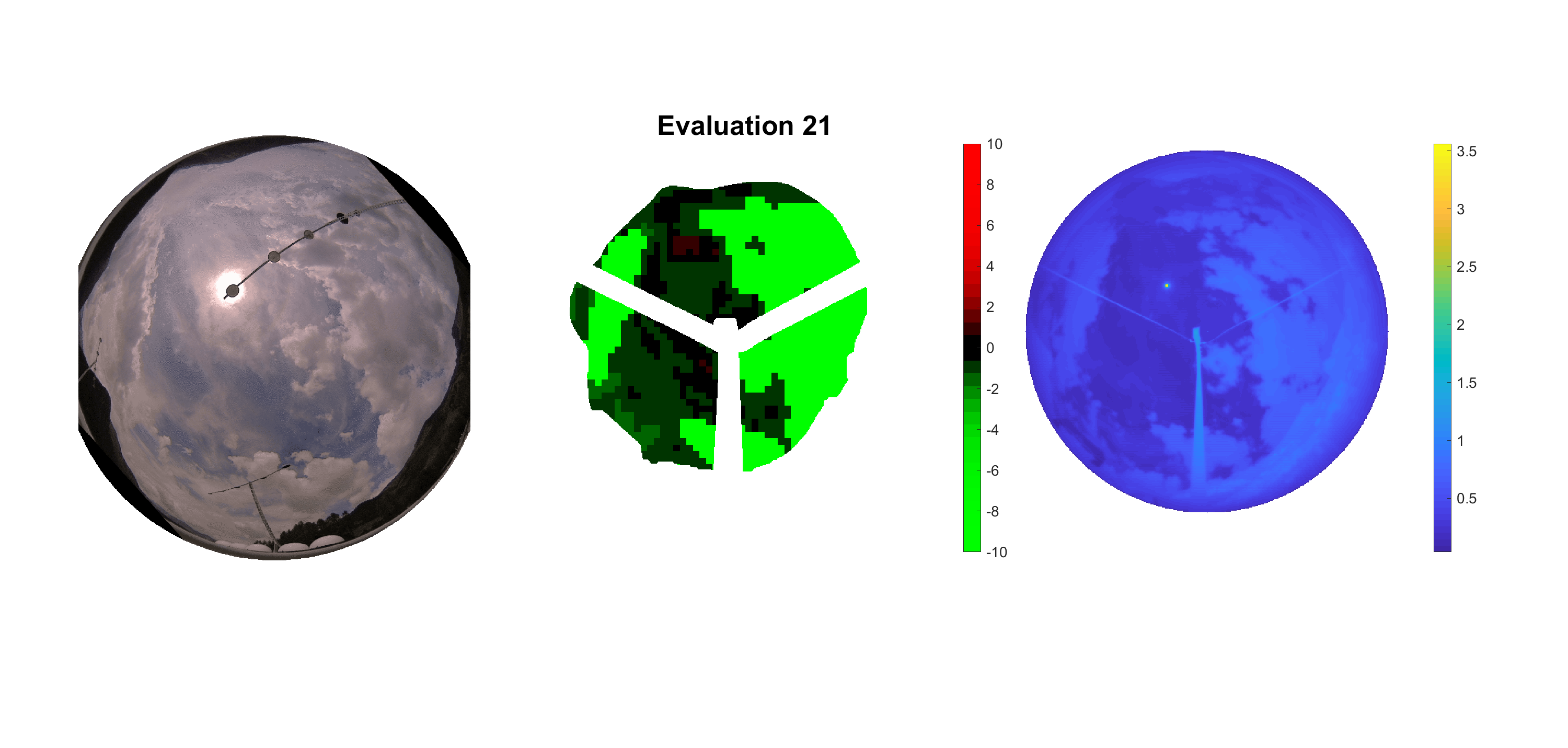
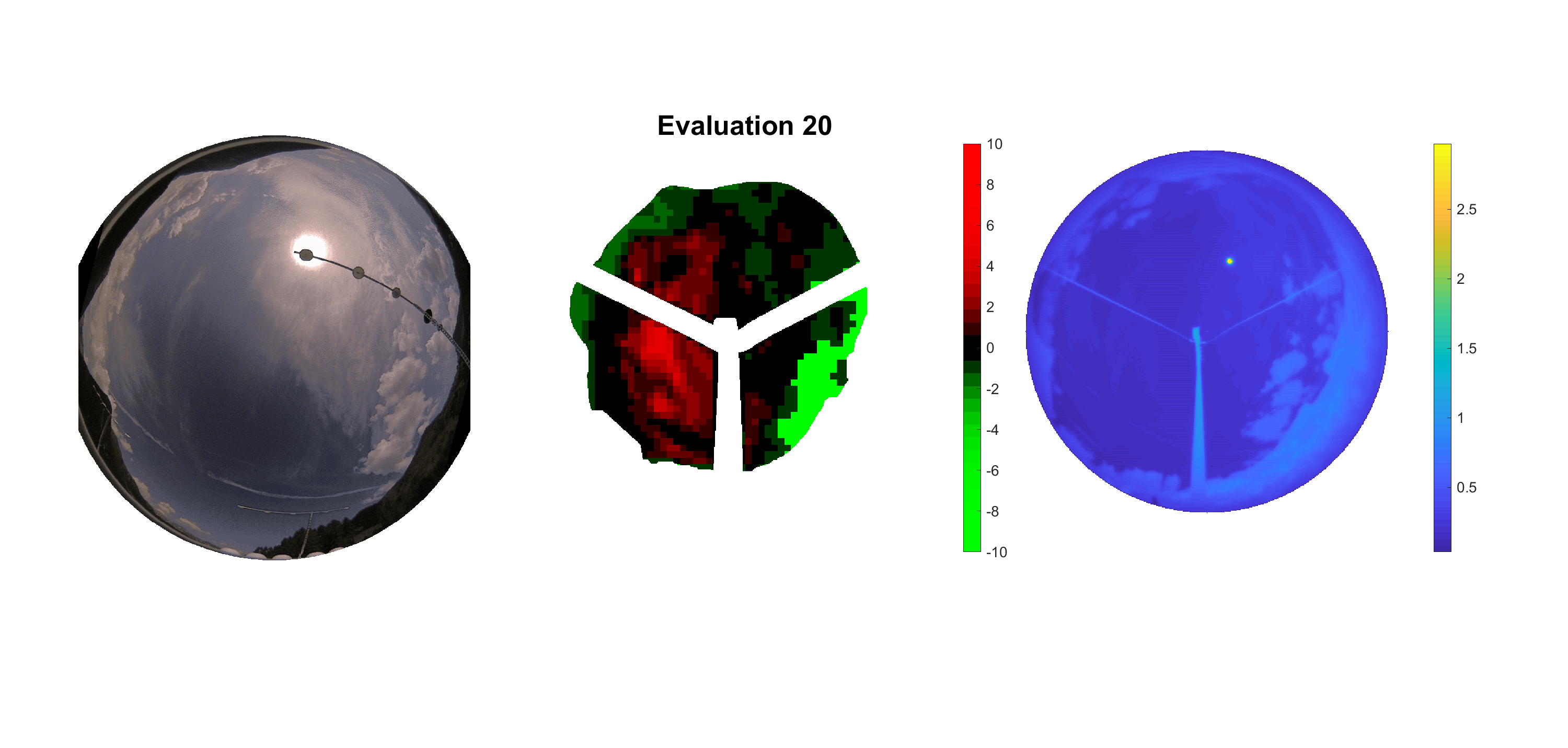

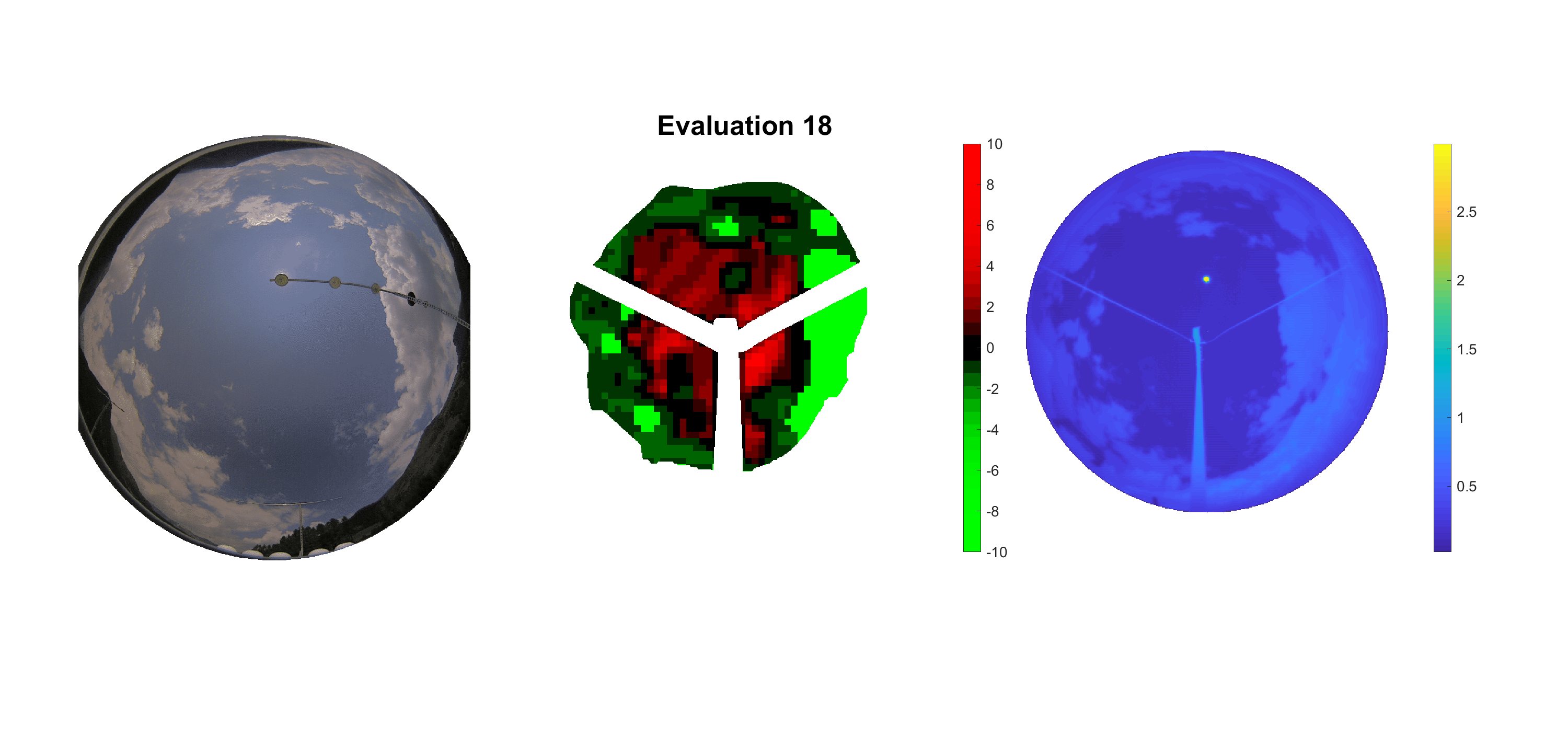
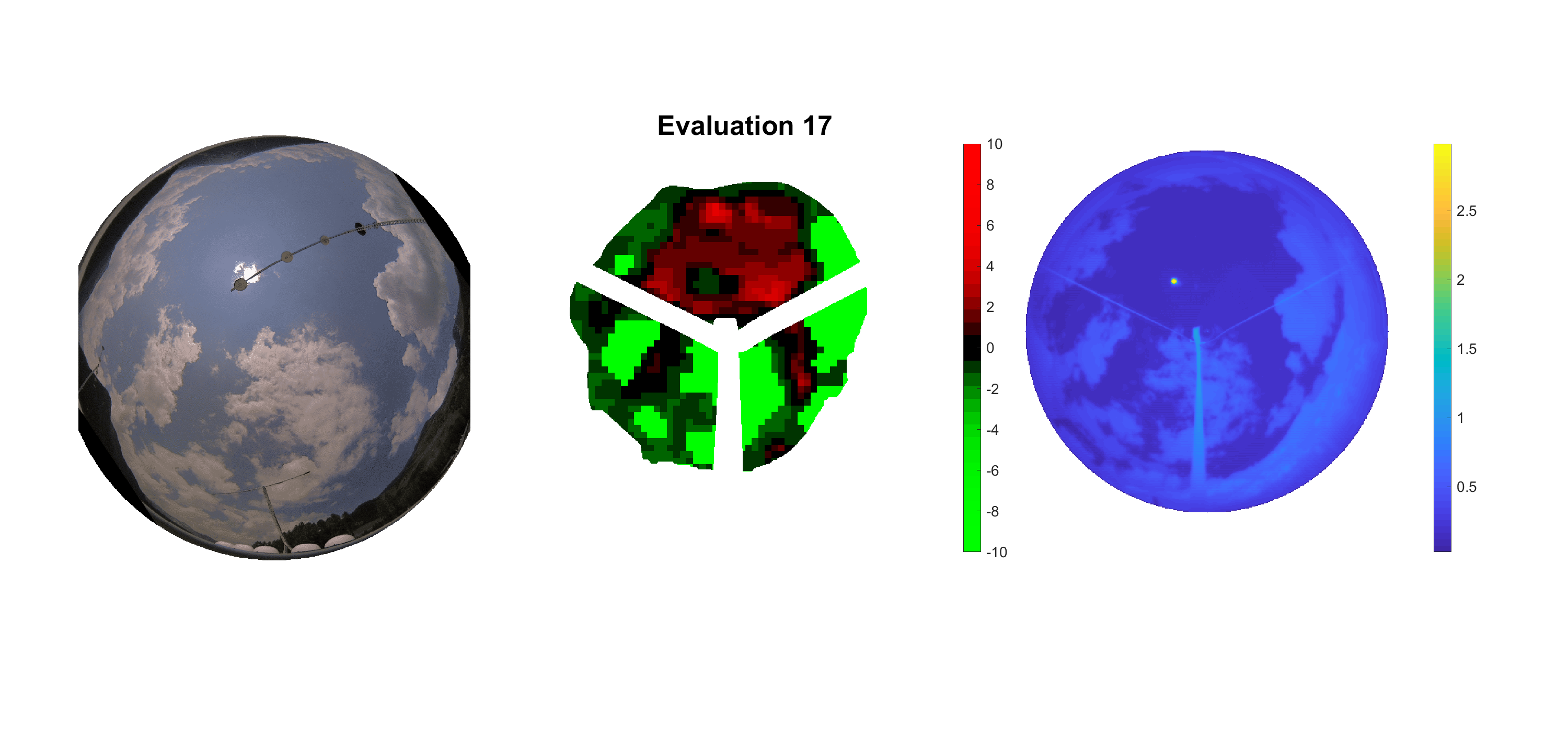

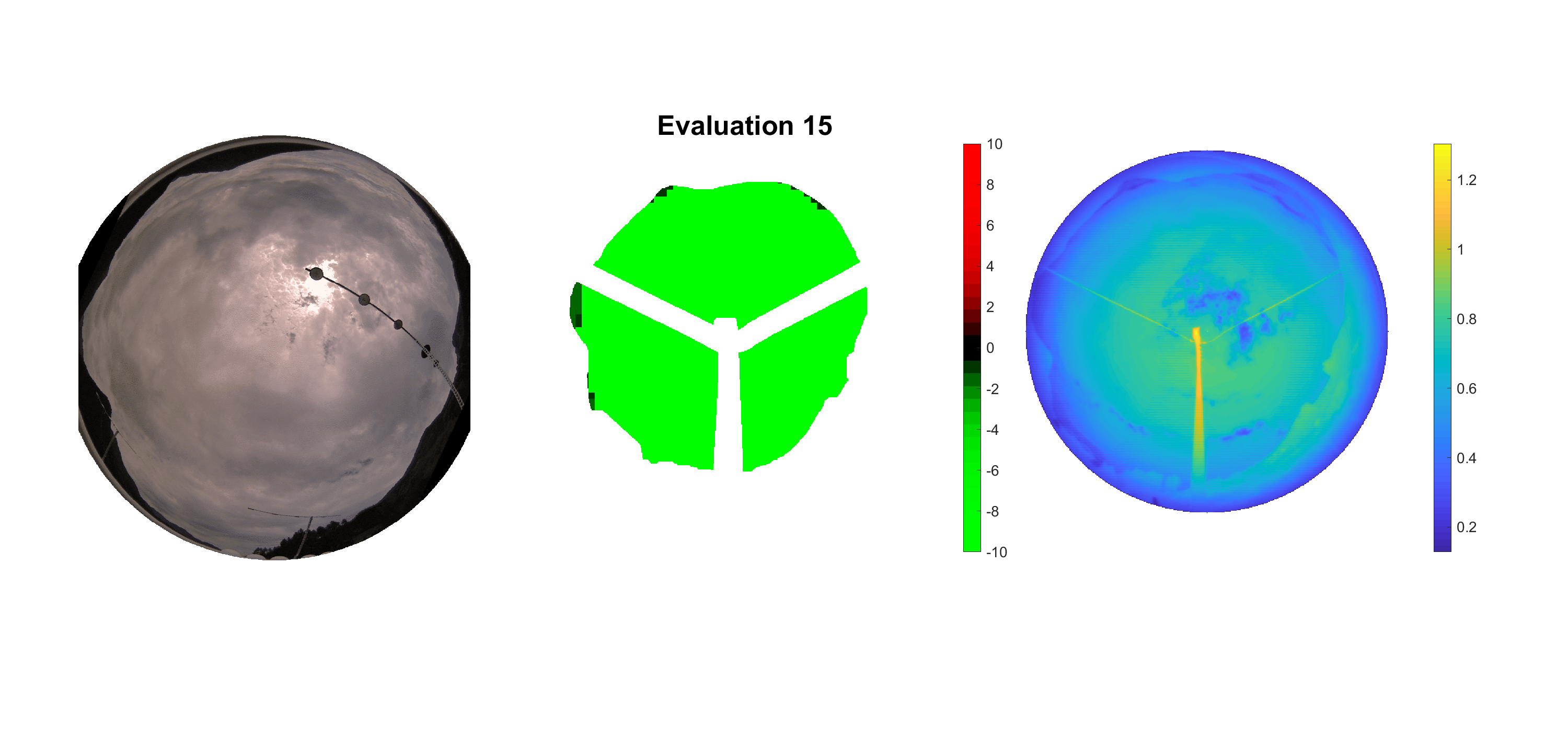
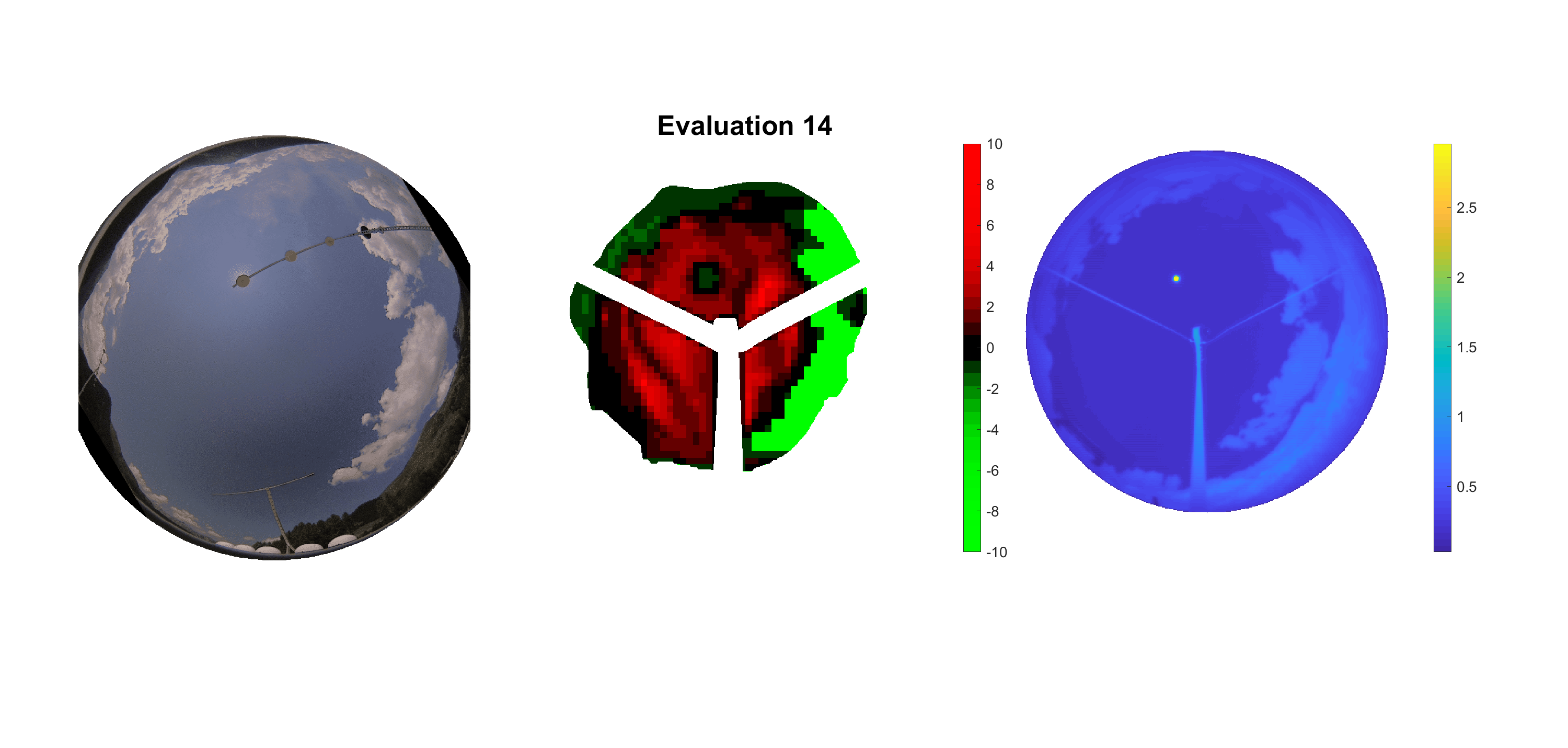
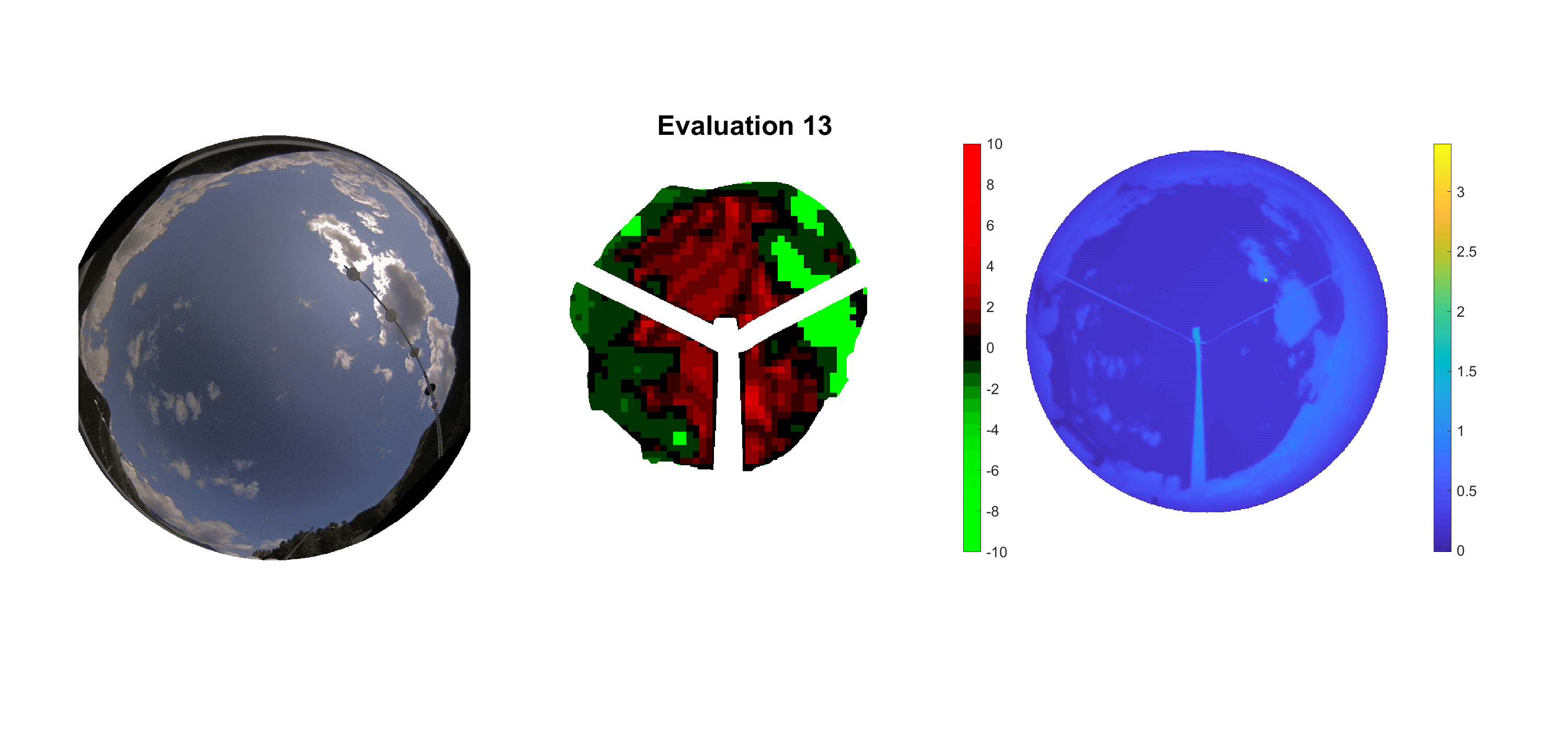
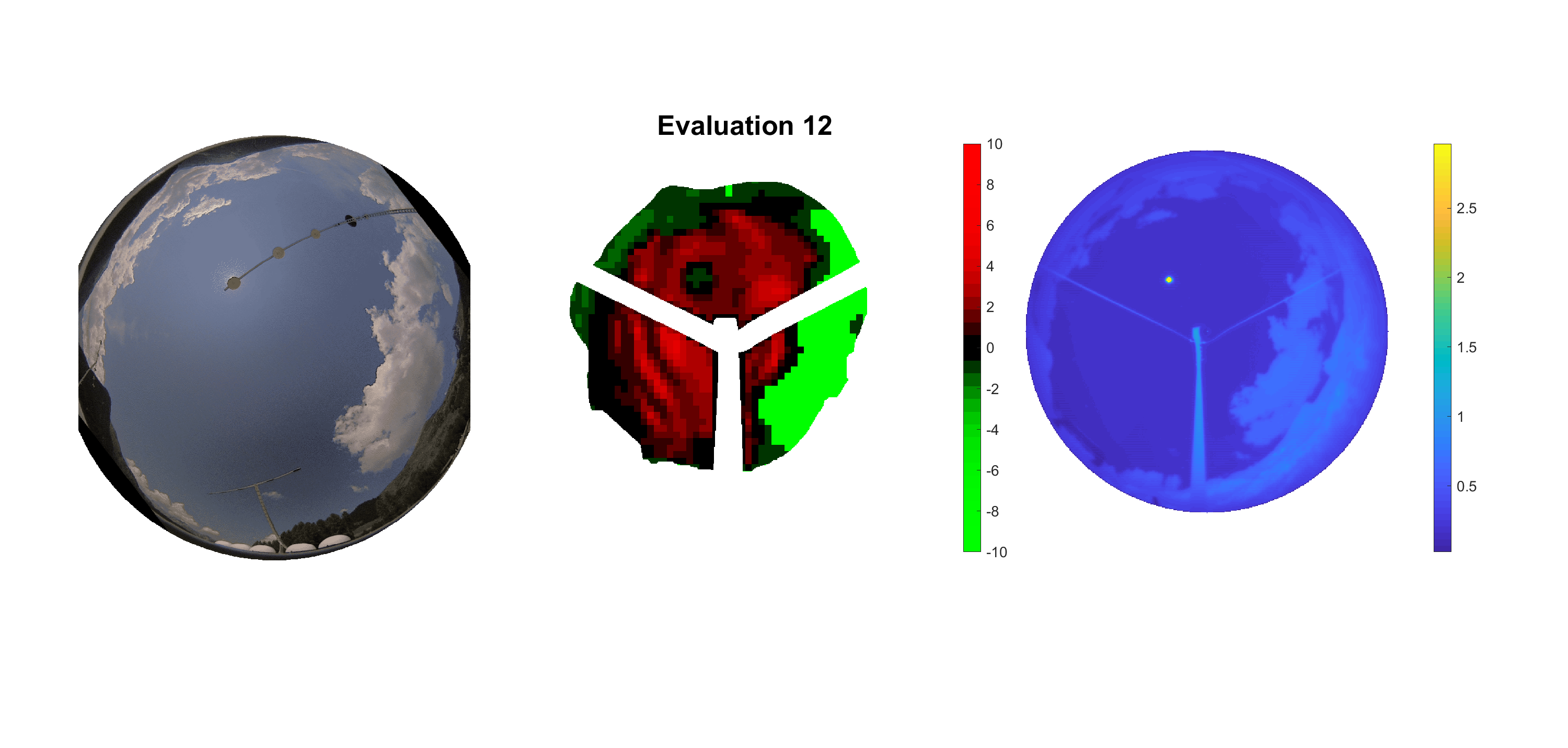


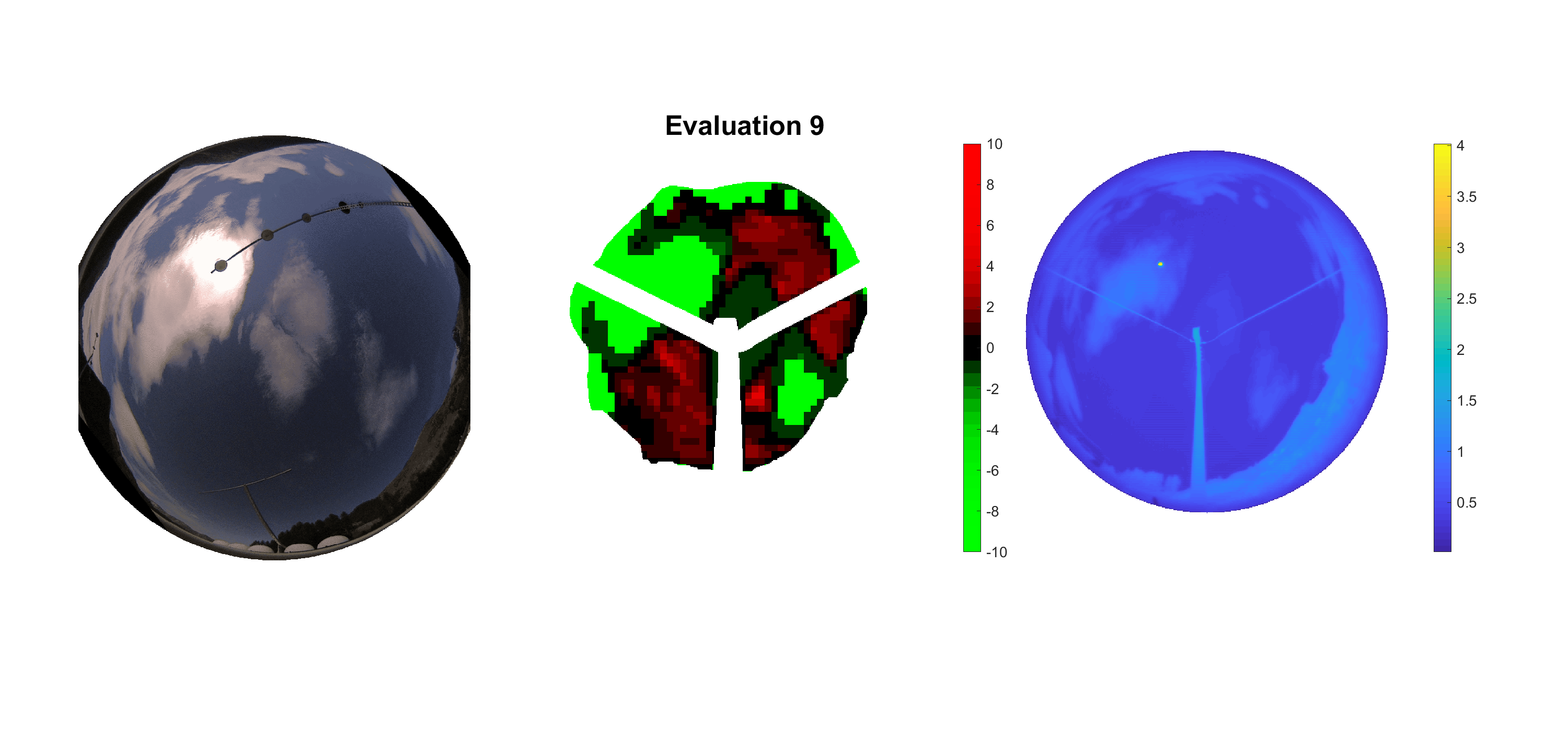


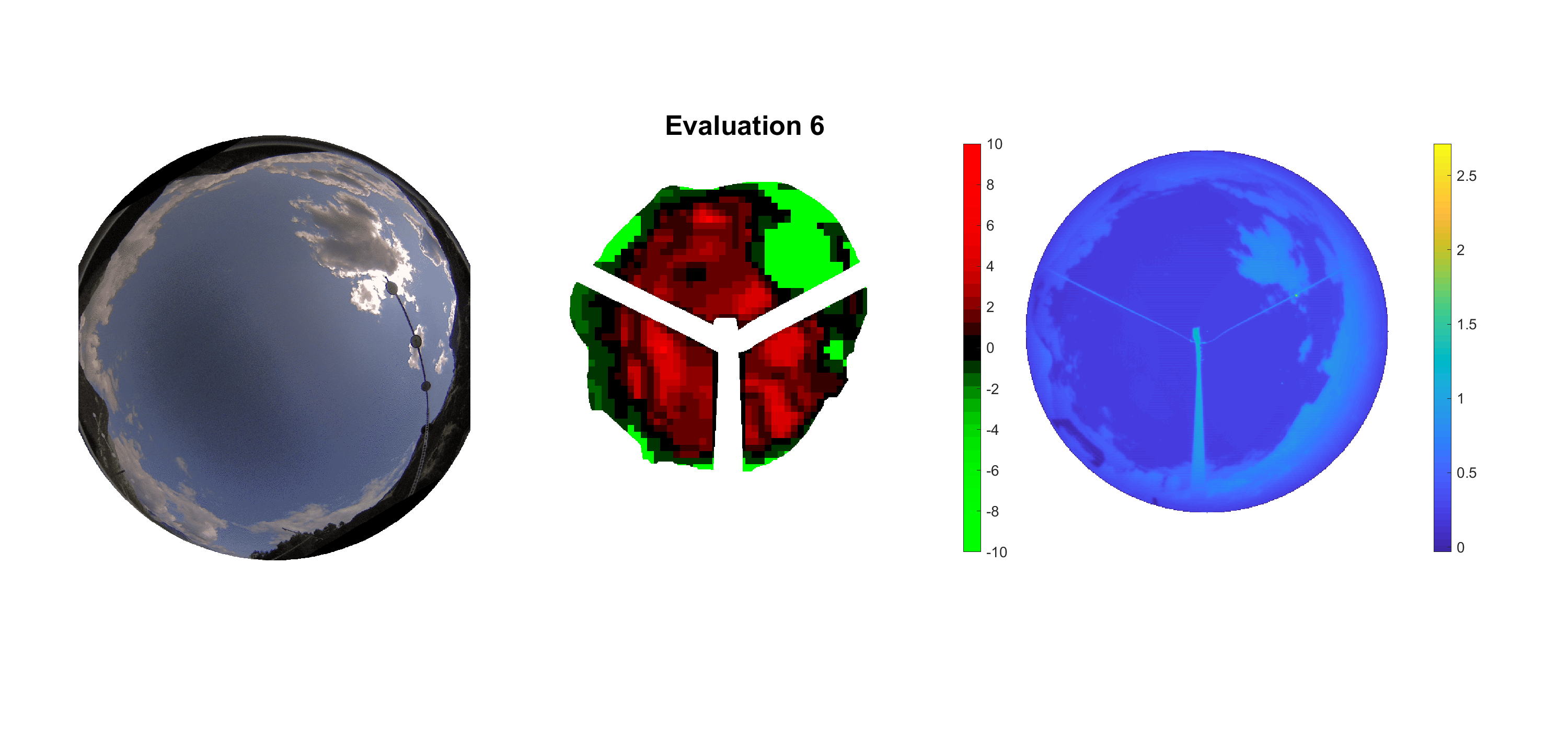
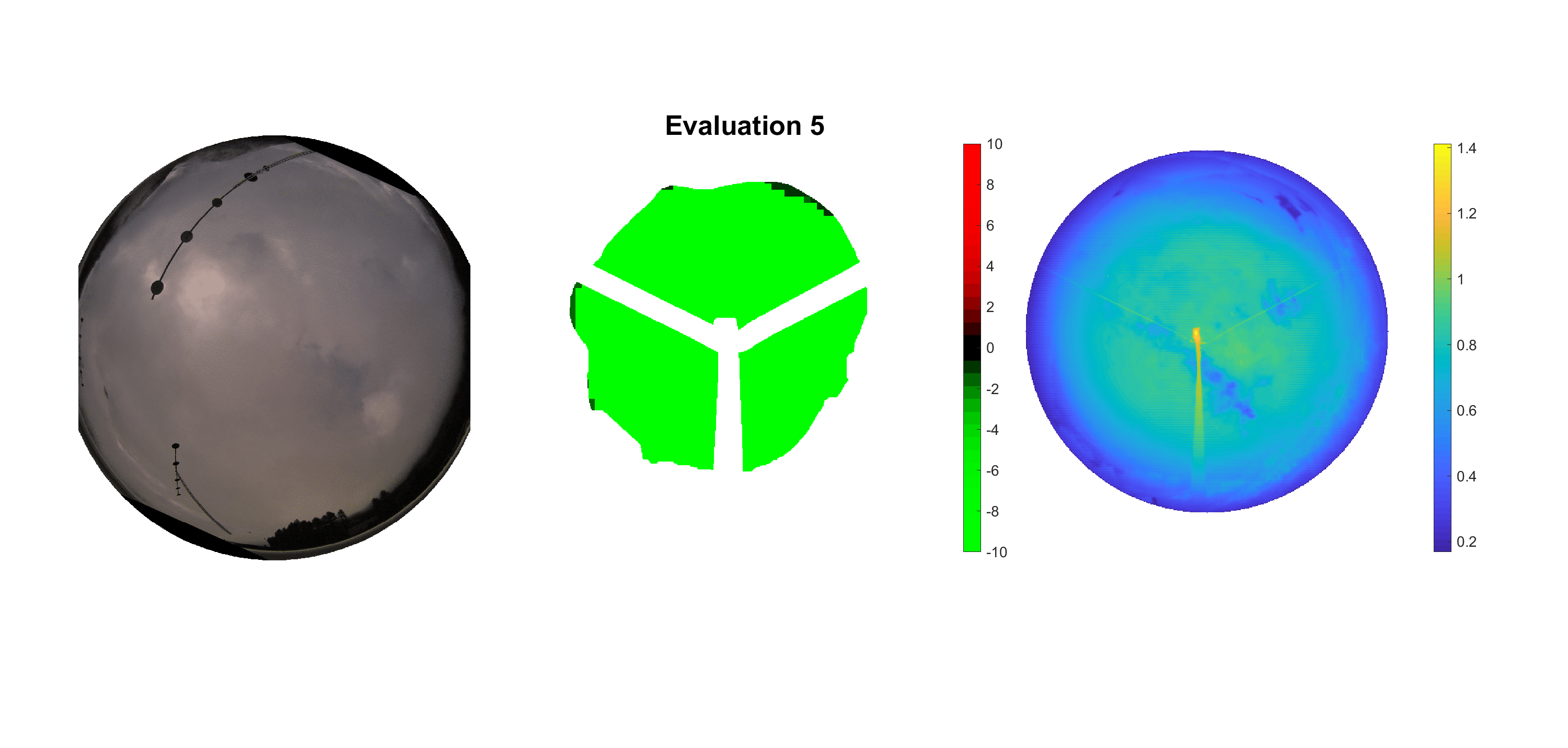



Die hellgrünen Bereiche wurden vom Grundprogramm bereits als Wolken erkannt. Die restlichen Bereiche werden dann vom linearen Classifier ausgewertet. Je röter ein Gebiet ist, desto sicherer ist sich der Classifier, dass es sich um unbedeckten Himmel handelt. Je grüner, desto eher entspricht das Gebiet einer Wolke. Der Algorithmus ist sicherlich noch nicht perfekt und kann und soll noch weiter verbessert werden. Aber bereits jetzt erkennt er auch die dünnen Wolken ziemlich gut.
Für Interessierte habe ich hier die Folien der Präsentation verlinkt, die ich am Ende meines Zivildiensteinsatzes gehalten habe:
Sie enthalten viele Details zum Algorithmus wie auch Ideen, wie er weiter verbessert werden könnte.
Eine abschliessende Bemerkung: ich bin sehr dankbar, dass ich während dem Zivildienst an einem so interessanten Projekt wie dem vorgestellten Wolkenalgorithmus arbeiten durfte! Daneben habe ich natürlich auch viele einfache Aufgaben wie Schneeschaufeln, das Putzen von Messgeräten und das Helfen in der Administration ausgeführt. Dies gehört dazu. Ich habe sie wohl gelegentlich (etwa beim Schneeschaufeln in der Kälte bei Gegenwind) verflucht, aber ich habe auch durch sie viel Nützliches gelernt.
Quellen
- Gröbner, J. et al.: “The infrared all-sky cloud camera at PMOD/WRC (IRCCAM),” 2016.
- Aebi, C., Gröbner, J., and Kämpfer, N.: “Cloud fraction determined by thermal infrared and visible all-sky cameras,” Atmos. Meas. Tech., 11, 5549- 5563, 2018.
- Luo, Q. et al.: “Cloud classification of ground-based infrared imagescombining manifold and texture features,” Atmos. Meas. Tech., 11, 5351- 5361, 2018.
- Brocard, E. et al.: “Detection of Cirrus Clouds Using Infrared Radiometry,” inIEEE Transactions on Geoscience and Remote Sensing, vol. 49, no. 2, pp. 595- 602, Feb. 2011.